My experience with Amazon Kendra


A couple months ago in a hackathon for Monzo I put together a lil team to complete the impossible:
"Organise theworld'sMonzo's information and make it easily searchable"
We ended up using Amazon Kendra, let's discuss my experience with it.
The problem
Like many companies, Monzo has a plethora of documentation across multiple apps. Notion, Dropbox, Google Drive, Slack, and GitHub to just name a few.
One of the larger problems we had was knowing roughly what we want to find, but not where to find it. For example, let's say service.emoji has a limit on how many emojis it can hold. We want to find both the decision record and the exact number.
We go to the code and see something like:
# Per the meeting with John we have set the limit to 15
limit = 15Okay, now we know there's context in this meeting. We then search Slack, Google Drive, Dropbox etc to find this meeting.
Eventually we find it and have context.
This is sub-optimal and may distract people for a while looking for information. If only there was some sort of engine which could search over things....
The solutions
In an ideal world we'll use a search engine and enter something like "service.emoji limit". The search engine would then return a bunch of results
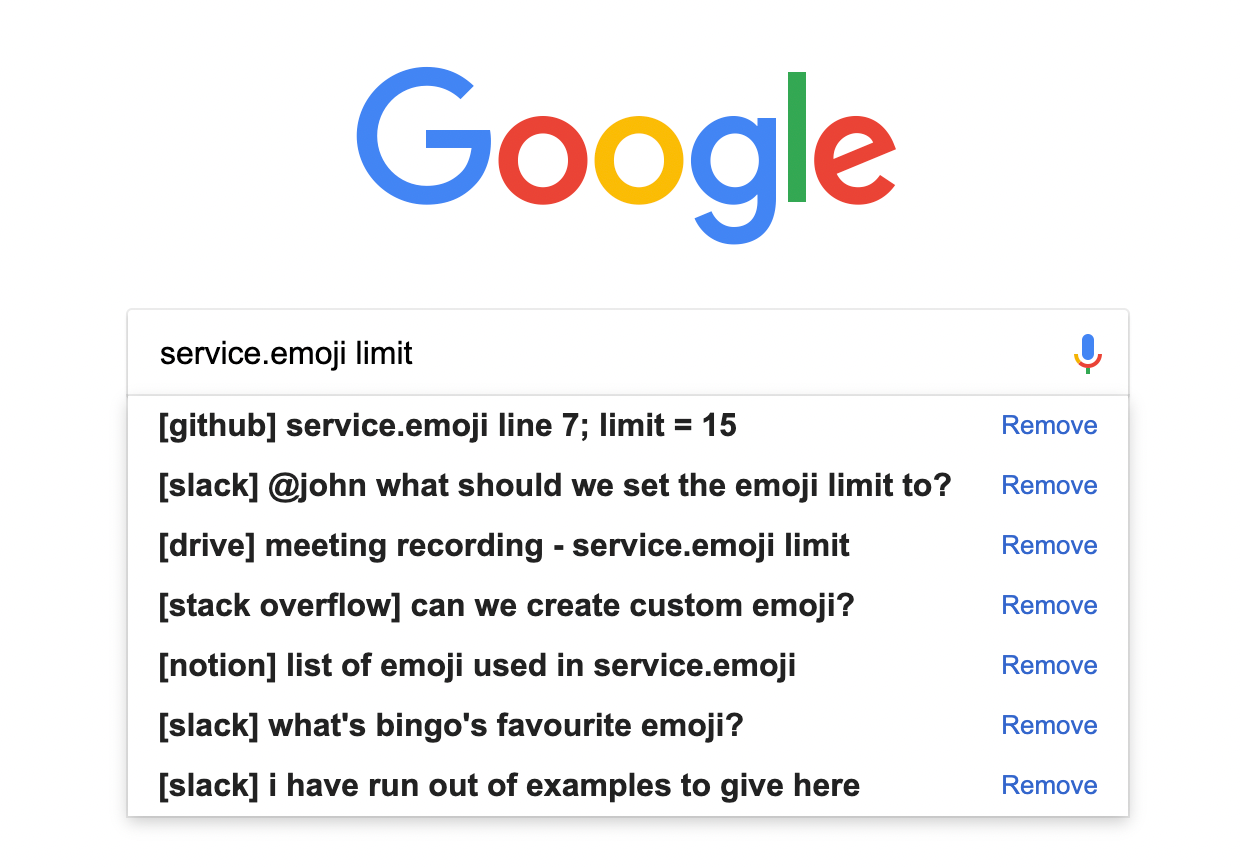
Now instead of us hunting for this information we get a lovely search result displaying not only the information we want, but also the location of it.
There's a bunch of ways we can do this.
Do it yourself
In theory we could create an Elasticsearch instance which would index every word across our documentation and we'd be able to search across all of it.
The problem with this approach is that we had 3 days to build something and there is a continued cost in maintaining applications. We wanted something faster.
Amazon Kendra
Amazon Kendra is a tool provided by AWS that promises to do exactly what we wanted.
You pay Amazon some sum of money (based on documents ingested, mostly) and they index your documents and let users search over it.
The Action
With my eyes set on Kendra, I decided to deploy a lil instance.
Deploying Kendra with Terraform isn't too hard:
resource "aws_kendra_index" "search_tool" {
name = "search_tool"
description = "Searches over internal documentation"
edition = "ENTERPRISE_EDITION"
role_arn = aws_iam_role.this.arn
}Something to note that is the docs use DEVELOPER_EDITION. This is intended for testing and is much cheaper, but comes with very serious constraints.
If you want to go from a DEVELOPER_EDITION to a ENTERPRISE_EDITION you have to effectively delete all of your already indexed documents and start over again. Be wary when picking this!
Once you have an instance deployed you get some fun things like....
TODO get screenshots of kendra
- There's a bunch of AWS documentation already added in, so you can play around with it.
- You can use the search tool
Conclusion
The good
- Docs on uploading documents not too helpful, quite confusing terminology around arguments and what they do
- automatic deduplication would be extremely cool, or even a "these 2 documents are very similar do u want to delete them"?
- More connectors, especially Notion
- It would be super cool to be able to deploy a very basic UI for searching Kendra in the console. While we built our own and can use the internal UI, I'd have very much enjoyed an external one.
- There's a lot of custom connectors out there, I am sensing a need for an
awesome-kendrarepo to monitor the connectors and other resources - I felt like Kendra could only really read text as text. Sometimes we'd have tables which were read incorrectly due to weird formatting (because of it being a table)
- How does the algorithm surface documents? What exactly happens when you click "thumbs up" "thumbs down"? I know this is "feeds into the AI magic" but we'd like some fancy white paper on the algorithm so we can understand how the system works
- A lot of our content was Markdown, Kendra supported markdown in the sense it was text – it'd be nice to natively support it (so it can detect links as links and not as
[this is a link](example.com))
The good
- Super easy to use, took around 3 days to build an MVP that people could use
- The AI algorithm was very very good at detecting what we wanted
- natural language processing was fantastic
- for the value it provides and how many documents we had in it, it was rather cheap