Tip: Use match statements instead of hash maps


Hashmaps are often touted as the fastest way to store & lookup data. They have O(1) constant time lookup, which means no matter what you look up it will always take the same amount of time. Whereas other search algorithms (Binary Search, for instance) take O(log n) time, which means if there are N items to search through it will have to search through log N items before it can find the one you want.
The basic premise is that we have some data, X, and we hash it hash(X). This points to a bucket in memory which is storing another data structure (a linked list or binary search tree) and usually our data is the first element of this structure.
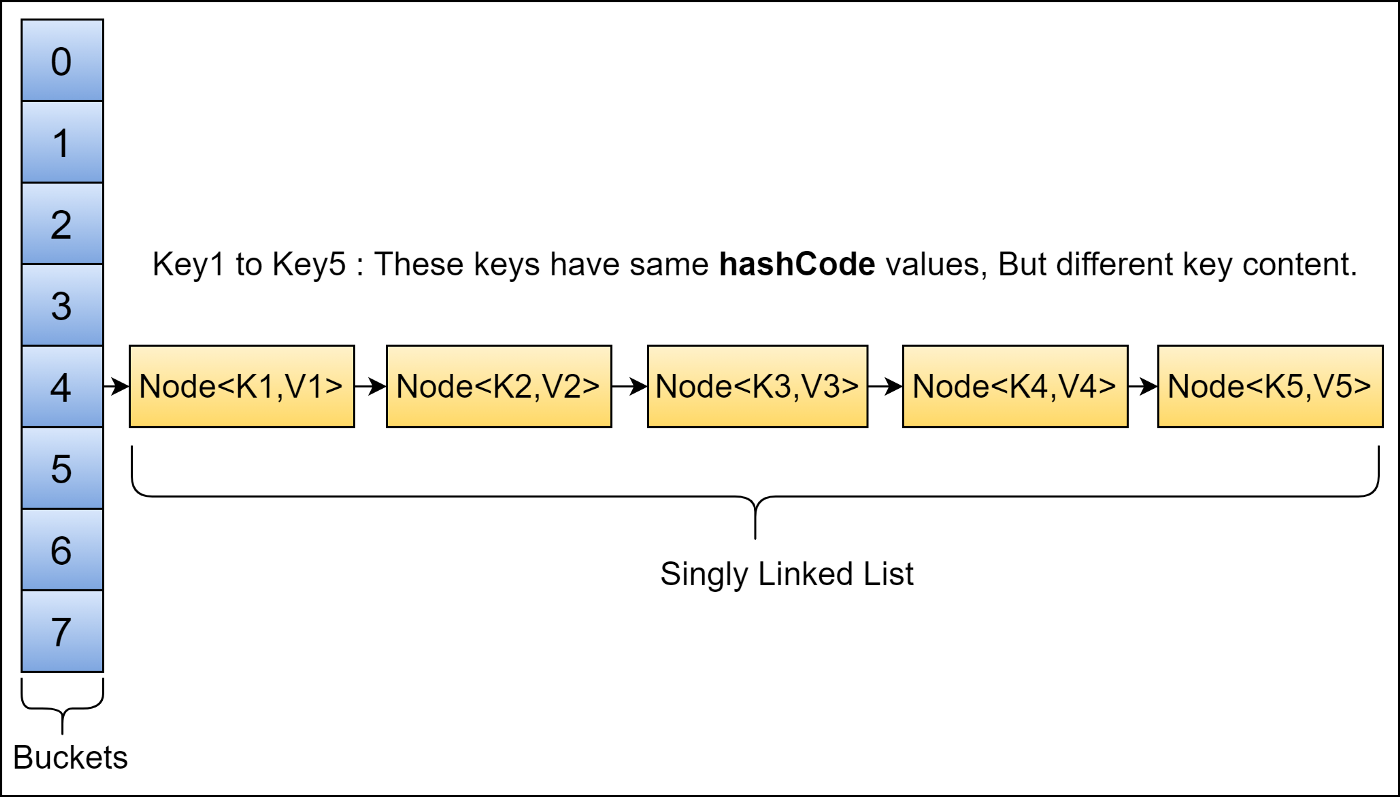
However, when it comes to real world time (not asymoptic times) it begins to falter. What if we were to hash 2 bits of data together and the hashes casue a collision, and we store 2 bits of data in the same area of memory?
In that case the language will have to use a datastructure (like a binary search tree or linked list) to find what you want, increasing the time it takes to locate data.
Or perhaps we insert a lot of data at the start of the program, during runtime, we have to calculate a lot of hashes. in a cppcon 2017 talk on Swisstable the authors state that across all of Google's code, they found a non-trivial amount of time was spent computing hashes 1.
In theory, hashmaps are good. But can we do better? We can change out the hashing algorithm to a more efficient one, we can lower how many items we insert into the hashmap to try and reduce the amount of collisions, but still – can we go faster?
Perfect hash table
If we just want to look up data, and we know all of the data at compile time – we can build a perfect hash table.
The process for hashmaps is:
- The program is ran.
- A hashmap is created with a backing datastructure (such as a binary search tree).
- For every piece of data given to it during runtime, it:
- Hashes the data
- Attempts to store it in the location the hash is pointing at
- If there is a collision, use the data structure (by making a new node)
Now when a user wants to find an item in a hashmap, they have to hash the data they are given and see if it is stored somewhere.
In contrast to a perfect hash table:
- The program is compiled, this happens before it is ran on the developers machine.
- The compiler turns our data into a lookup table, which is the fastest way to look up data on a CPU.
- That's it. When the user runs our program, the table is already made so they spend no time hashing or alloting data or searching data structures when there is a collision.
Because this happens at compile-time, the executable binary for a perfect hash table will be larger than one using a hashmap, however both will use roughly rhe same amount of RAM.
How do I use a perfect hash table?
Remember, perfect hash tables have 2 requirements:
- No data is inserted into them at runtime.
- All data is known at compile time.
With that in mind, we can use a match statement to make the compiler turn it into a perfect hash table like below:
let result = match text {
".-" => "A",
"-..." => "B",
"-.-." => "C",
"-.." => "D",
"." => "E",
"..-." => "F",
"--." => "G",
"...." => "H",
".." => "I",
".---" => "J",
"-.-" => "K",
".-.." => "L",
"--" => "M",
"-." => "N",
"---" => "O",
".--." => "P",
"--.-" => "Q",
".-." => "R",
"..." => "S",
"-" => "T",
"..-" => "U",
"...-" => "V",
".--" => "W",
"-..-" => "X",
"-.--" => "Y",
"--.." => "Z",
_ => return None,
};When the program is compiled, the compiler turns it into a lookup table. We can see this on Godbolt.
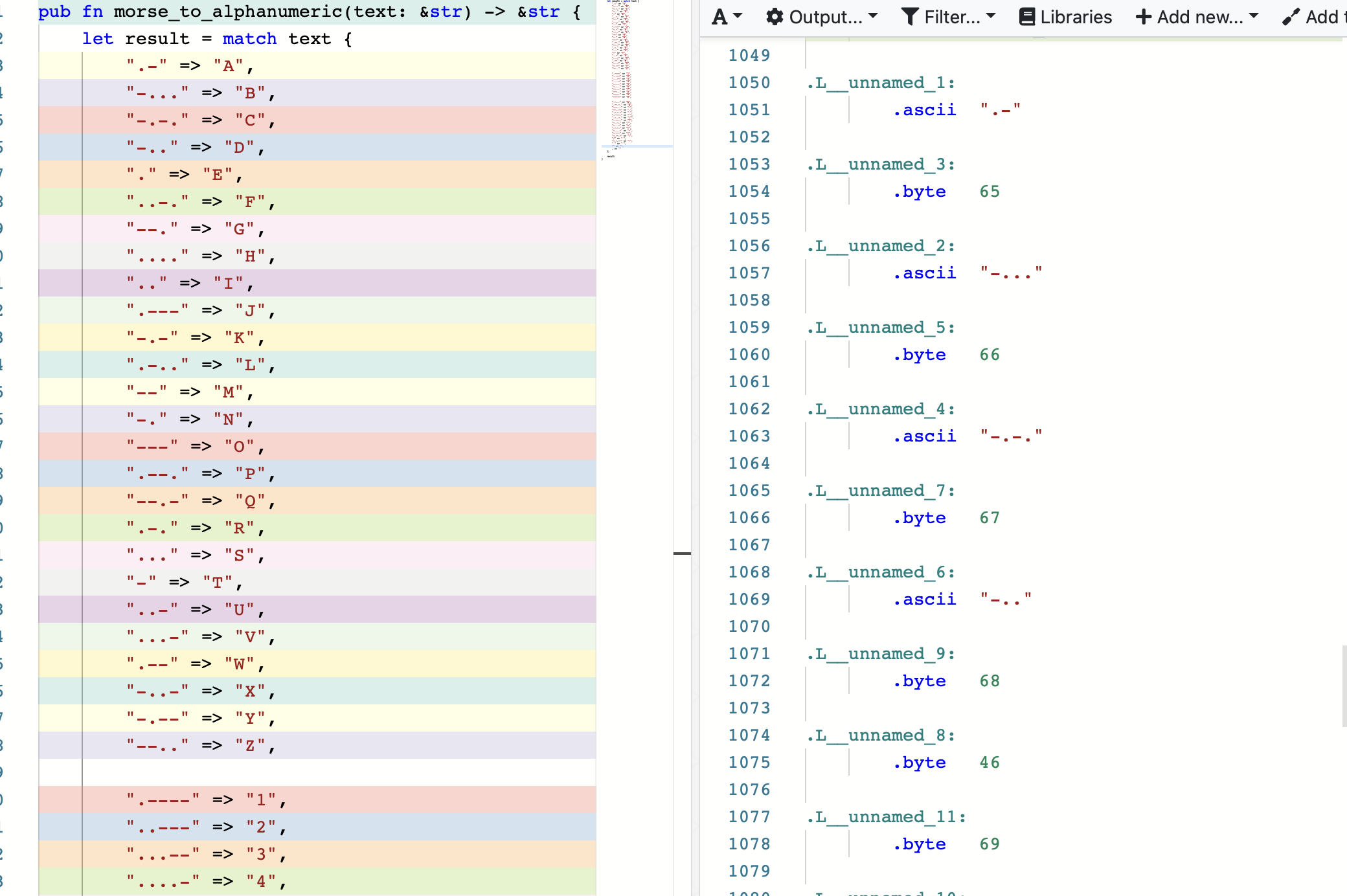
This results in about 1000 lines of assembly.
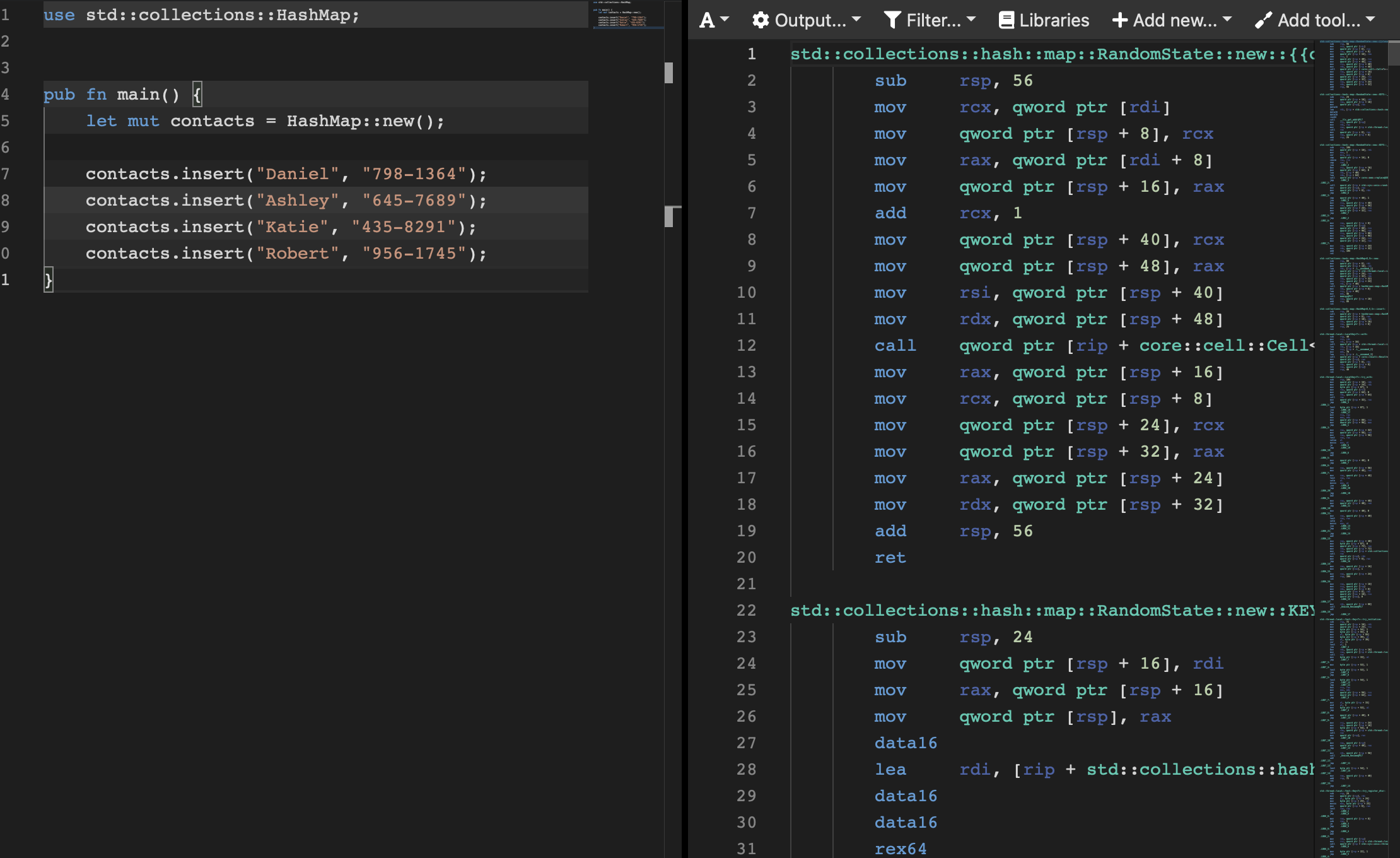
For a hashmap like below:
use std::collections::HashMap;
pub fn main() {
let mut contacts = HashMap::new();
contacts.insert("Daniel", "798-1364");
contacts.insert("Ashley", "645-7689");
contacts.insert("Katie", "435-8291");
contacts.insert("Robert", "956-1745");
}This results in about 6000 lines of code and there is significantly more code to handle adding things to the hashmap.