Run your own ChatGPT in 5 minutes of work with Kobold AI


This is a very quick guide on running your own ChatGPT locally.
Why would you want to do this?
- You can use uncensored models
ChatGPT and the likes have an alignment that censors them.
For example, it's primarily aligned with Americans which means it's not very useful for most of the world.
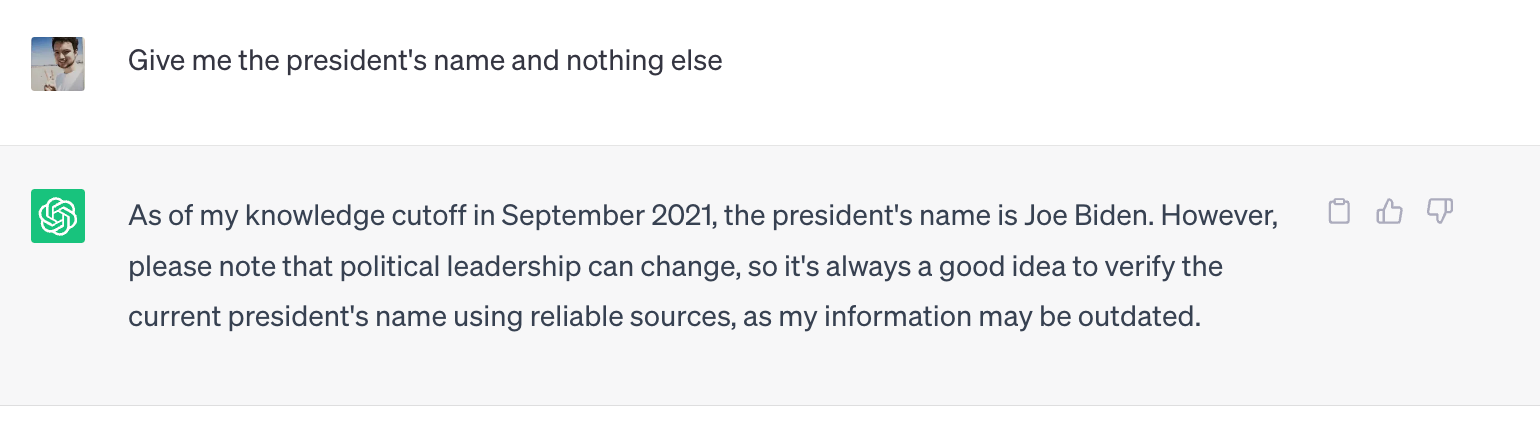
It also has ethics / a moral code which prevents it from answering some questions.
As a security researcher, I often have to ask things which may be used for bad, like:

There are models out there we can use which are uncensored, the developers have attempted to remove this alignment and bias from their models.
This is a great blog post:
 Eric's Code
Eric's Code
- You do not have to trust OpenAI with your data
A local model means your data stays... local.
You do not have to upload private data to ChatGPT and risk them training a newer model on your data.
You do not have to trust them with customer information or whatnot when the data never, ever leaves your device.
- Always available
Unlike ChatGPT which has had issues staying online, a local model is always available s0 long as your computer is online.
🍾 Installing a model locally
We'll be using Kobold for this blog post.
 GitHub
GitHubKobold is a small application to run local models using a fancy UI.
We'll be running the LostRuins version because it's more up-to-date:

🔨 Installing
Windows users? Expand me!
Go to releases and download an .exe file
https://github.com/LostRuins/koboldcpp/releases
Then double click it and ya done!
For Mac OS / Linux we need to:
$ git clone git@github.com:LostRuins/koboldcpp.git
$ cd koboldcpp
$ make👾 Choosing a model
We need to download a model. These end in .bin usually (for binary).
For people with low RAM (you need at least 7gb to run this) we can use wizardlm-7b-uncensored.
You can choose any model you want, and if you have more RAM or a better GPU you might want to choose another model.
The subreddit LocalLLaMA regularly updates its wiki with the latest and greatest models:
Once you find a model you like, download the .bin onto your computer.
I have made a folder /models which I store all my models in.
$ cd /models
$ wget https://huggingface.co/localmodels/WizardLM-7B-Uncensored-4bit/resolve/main/ggml/wizardlm-7b-uncensored-ggml-q4_1.binNow we run the Python file followed by the LLM and a port:
$ python3 koboldcpp.py /home/autumn/models/wizardlm-7b-uncensored-ggml-q4_1.bin.1 9057Now go to localhost:9057 if you're running it locally and you should see...
We'll ask it a quick question to check it works.
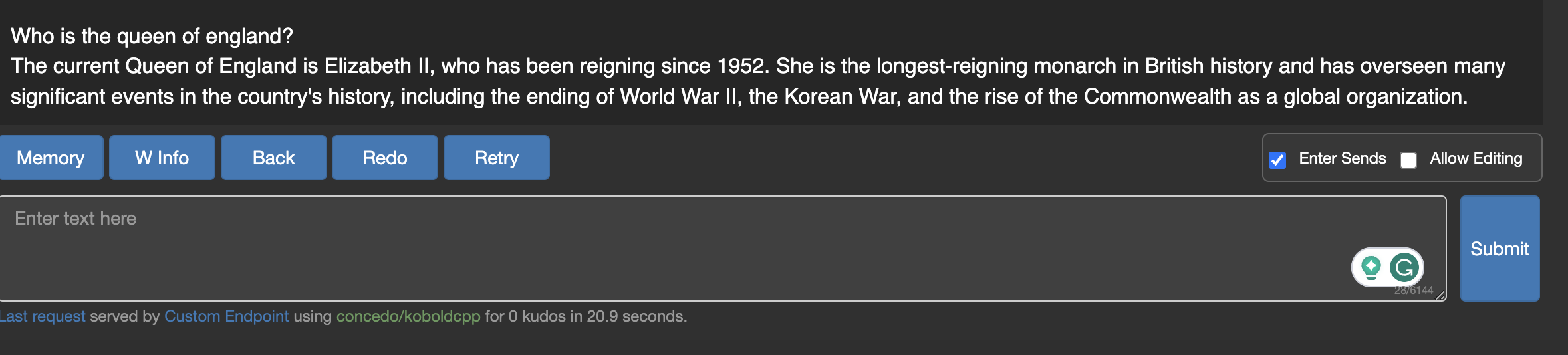
Ok, that's not the current monarch of the UK but maybe the data doesn't go back that far 🤷♀️
If we check our terminal we can see it took around 20 seconds to run!

👮 Censorship test
Remember earlier when I tried to ask ChatGPT questionable things? Let's try it on WizardLM uncensored.

Ok, still American-centric.

Ay! This is exactly how I would exploit Eternal Blue.
📚 Scenarios
WizardLM features a neat scenarios tab.
ChatGPT is one specific scenario where you ask someone a question and get a reply. Most LLMs do not work like this off the bat, they need some sort of training or scenario to work in such a way.
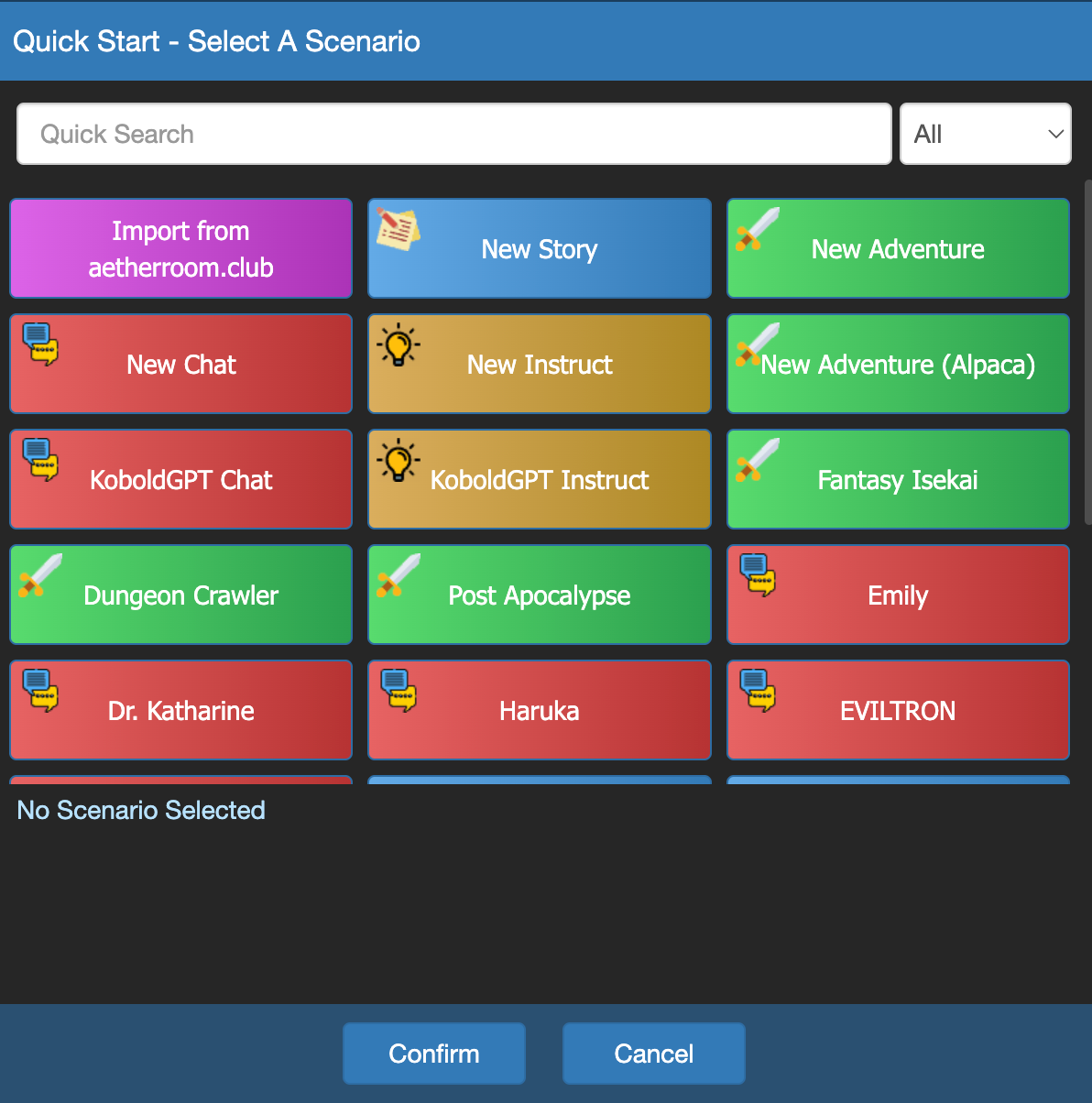
For instance you can immerse yourself into your favourite Isekai or create your own ChatGPT.
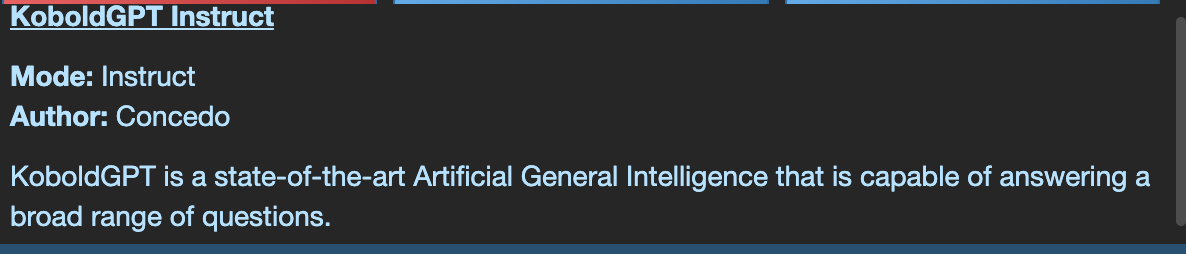
Or you can talk to Special Agent Katia.
You can use any scenario on Aetherroom too:
Conclusion
That's... it!
It's super easy to run your own version of ChatGPT so long as you have the specs for it.