Speeding up Game Sentence Miner (GSM) Statistics by 200%


Over the course of a weekend in-between job interviews I decided to speed up the loading of statistics in one of my favourite apps, GSM.
GSM is an application designed to make it easy to turn games into flashcards. It records the screen with OBS and uses OCR / Whisper to get text from it. You then hover over a word with a dictionary, click "add to Anki" and GSM sends the full spoken line from the game + a gif of the game to your Anki card.

GSM has a statistics page contributed by me, every time you read something in-game it adds it to a database which I then generate statistics from.
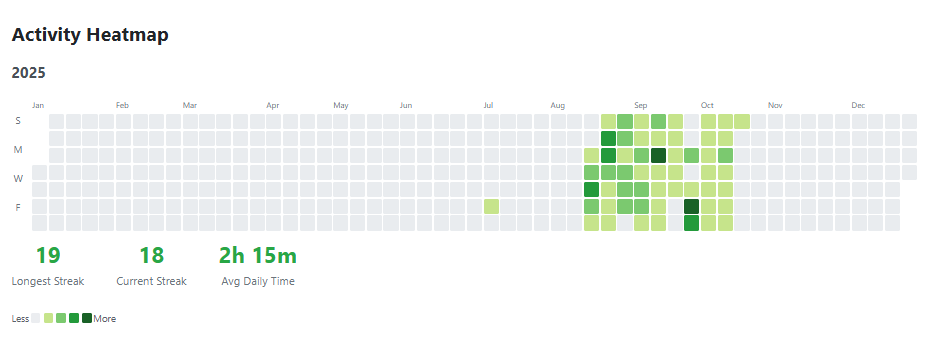
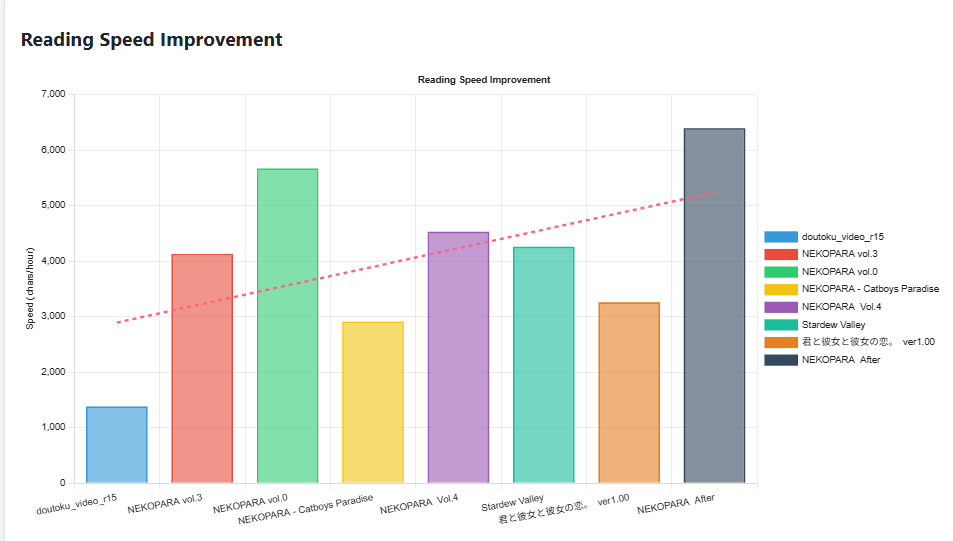
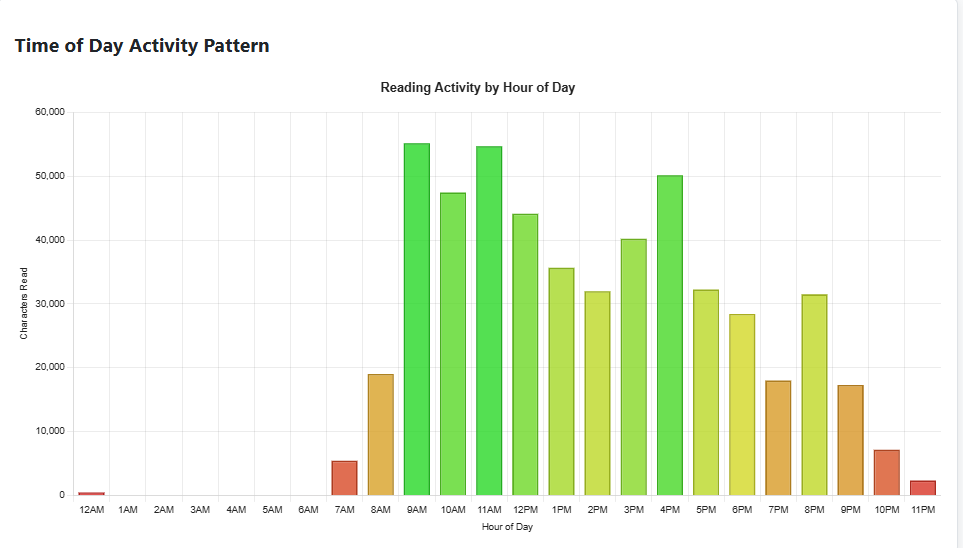
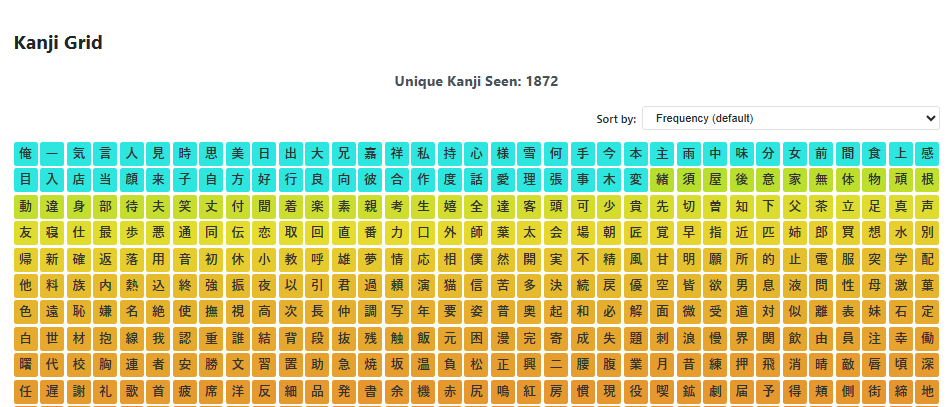
Some stats for ya
These stats take a while to load.
- /stats takes 6 seconds
- /anki takes around 40 seconds
- /overview takes around 4 seconds
And I added /overview because /stats was too slow!
.exe, that serves Flask entirely locally. These times are absurd for a local app!This blog post talks about how I spent my weekend improving the loading speed of the website by around 200%
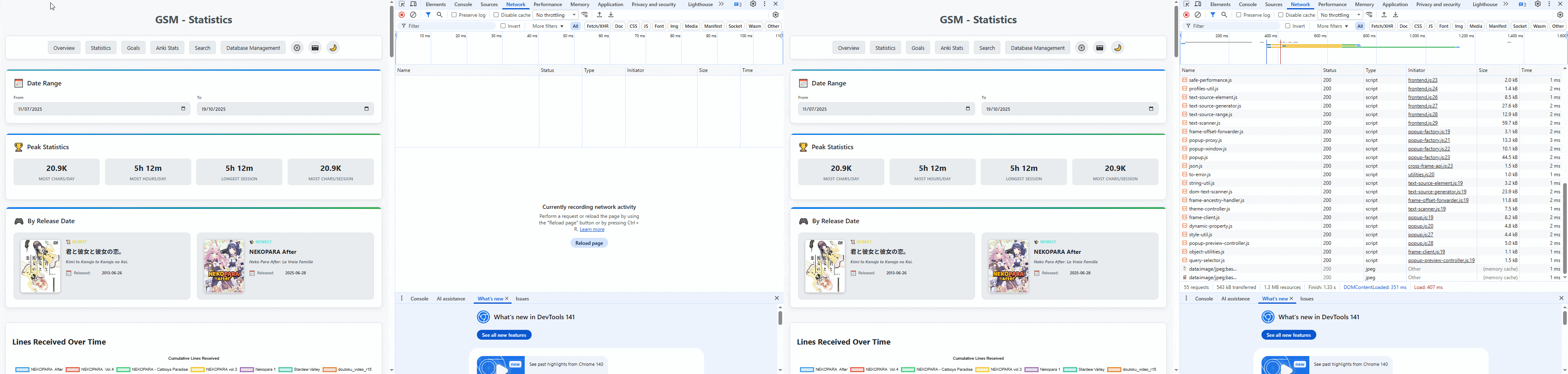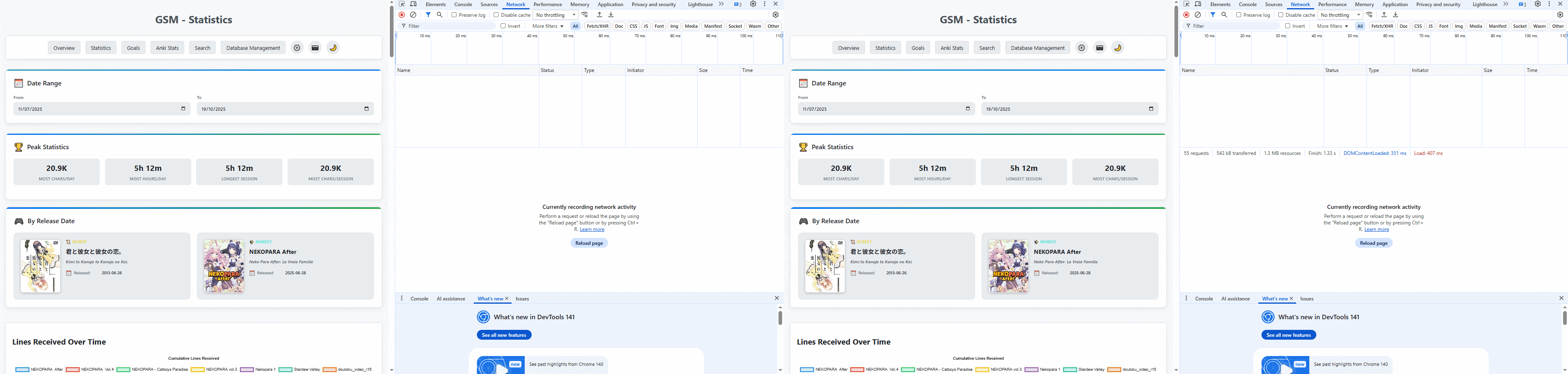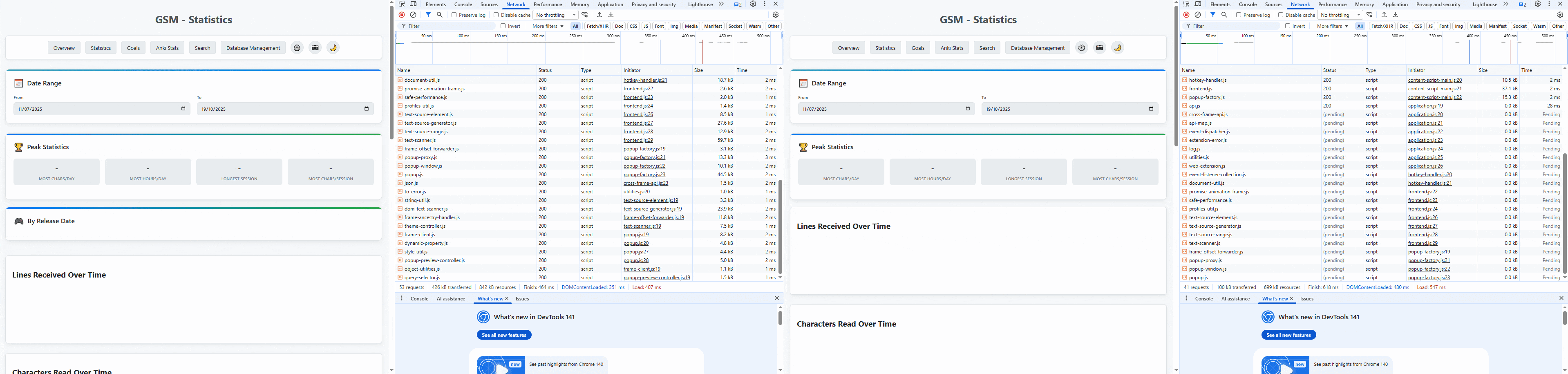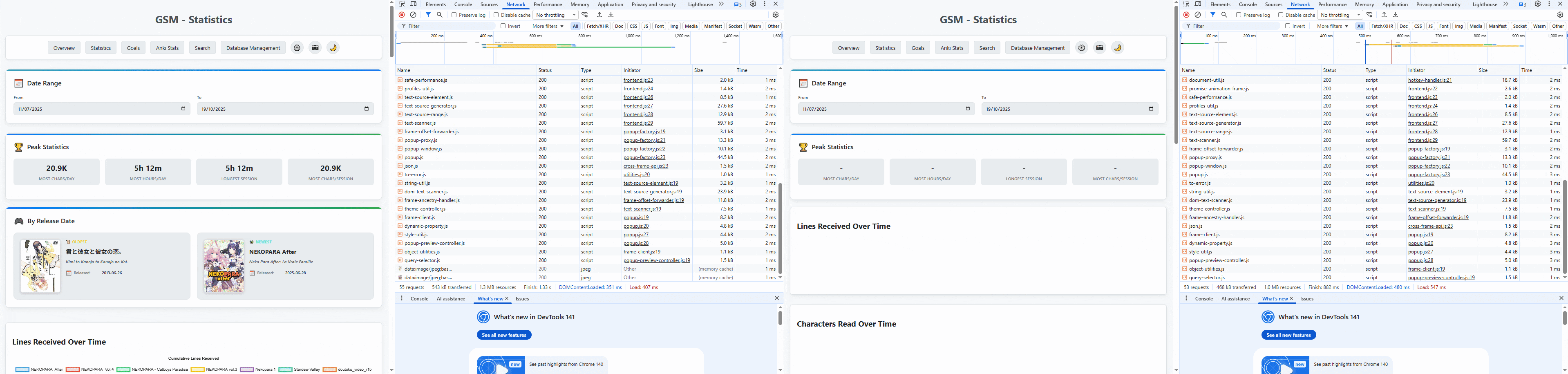
Why does statistics take so long to load?
The entire database is one very long table called game_lines.
Every single time a game produces a line of text, that is recorded in game_lines with some statistics.
Each line looks like this:
e726c5f5-7d59-11f0-b39e-645d86fdbc49 NEKOPARA vol.3 「もう1回、同じように……」 C:\Users\XXX\AppData\Roaming\Anki2\User 1\collection.media\GSM 2025-08-20 10-35-15.avif C:\Users\XXX\AppData\Roaming\Anki2\User 1\collection.media\NEKOPARAvol.3_2025-08-20-10-35-28-515.opus 1755648553.21247 ebd4b051-27aa-4957-9b50-3495d1586ec1Or in a more readable version:
🗂 Entry ID: e726c5f5-7d59-11f0-b39e-645d86fdbc49
🕒 Timestamp: 2025-08-20 10:35:15
🔊 Audio: NEKOPARAvol.3_2025-08-20-10-35-28-515.opus
🖼 Screenshot: GSM 2025-08-20 10-35-15.avif
🦜 Game Line: "「もう1回、同じように……」"
📁 File Paths:
C:\XXX\AppData\Roaming\Anki2\User 1\collection.media\GSM 2025-08-20 10-35-15.avif
C:\XXX\AppData\Roaming\Anki2\User 1\collection.media\NEKOPARAvol.3_2025-08-20-10-35-28-515.opus
🧩 Original Game Name: NEKOPARA vol.3
🧠 Translation Source: NULL
🪶 Internal Ref ID: ebd4b051-27aa-4957-9b50-3495d1586ec1
📆 Epoch Timestamp: 1755648553.21247
Then to calculate statistics, we query every gameline.
For me this takes around 10 seconds.
If you play a lot of games it can take around 1 minute....
All the statistics you have seen so far are calculated from this data alone, there's some easy things like:
- How many characters of this game have I read?
- How long have I spent playing it?
- What's the most I've read in a day?

But in the Japanese learning community there is 1 important bit of data everyone wants.
How many characters do I read per hour on average? What is my reading speed?
This is important because we know how many characters is in a game, if we know our reading speed we can work out how much of a slog it will be.
On a site like Jiten.moe we can insert our reading speed into the settings and see how long it'll take to read something.
At my very nooby reading speed of 2900 characters / hour, it'll take me 550 hours of non-stop reading to play Fate/Stay Night.
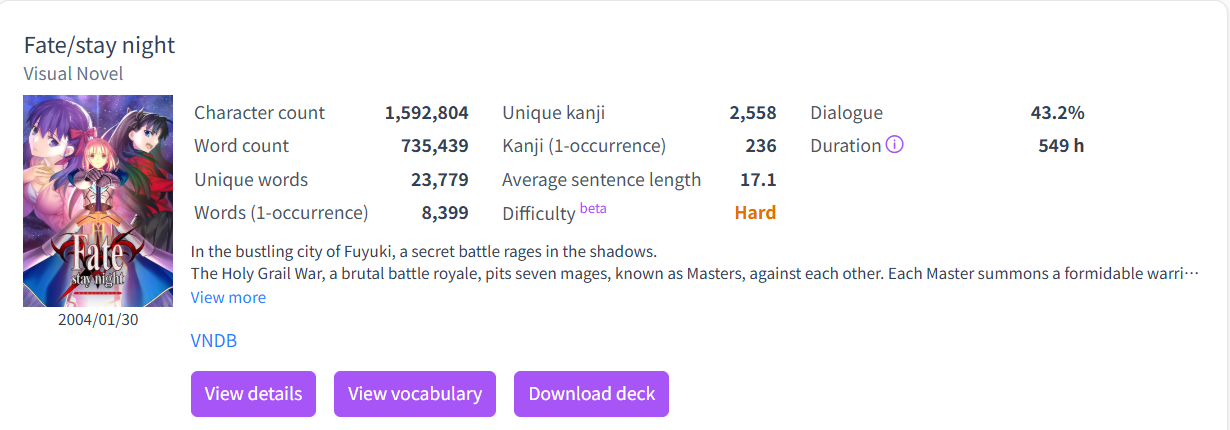
Although this is one of the most famous visual novels of all time and has been made into numerous anime, spending 550 hours slogging through it does not seem good.
Knowing my reading speed allows me to pick games / visual novels that I can do in a few weeks rather than a year or more.
Now looking at our data there is no easy way to calculate this, right? Games do not tell you "Oh yeah in this Call of Duty dialogue you read at this pace".
Other similar sites like ExStatic calculate this:
But interestingly they have sorta the same data as us.
- Game: Reverb
- Line: 「ホタカさーん!ホタカさーん!」
- Timestamp: 1755612879.053
But let's say we get 4 game lines come in. Each one is of length 10.
They come in every 15 minutes.
So our average reading speed is 40 characters per hour.
But then the next day, 24 hours later, we read another line of 10 characters.
Now our averaging reading speed is skewed to be much lower because in our code it looks like it took us 24 hours to read 10 characters.
The absence of data is data itself here, but how is everyone in the Japanese learning community handling this?
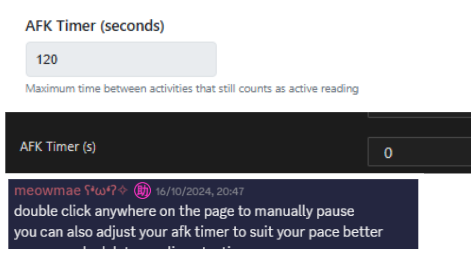
Everyone sets an AFK Timer.
If you do not get a new line within the timer, it assumes you are AFK and stops counting towards your stats.
This may seem uninteresting now, but this powers many of our design choices later on.
What should we do?
We have a couple of things we can do to speed up the loading of the stats site.
- Batch all API calls into one
Currently we get all game lines multiple times calculate the stats that way. It's not as clear cut as 1 bar graph == 1 DB call. It's more like one section grabs all game_line and alters it to work for that section.
This makes a lot of sense, but sadly it doesn't work so well.
I've already tried this:
Ignore my bad PR etiquette. We talked more about this in the Discord. I don't want to write conventional commits + nice PRs for a very niche tool 😅
Firstly, it only saves around a second of time. We still have to pull all the game lines no matter what.
Secondly, this makes it much harder and more rigid to calculate statistics. We had one API call, and then we calculated every possible statistic out of that one call and put it into a dictionary.
It's a bit... hardcore...
We basically had one 1200 line function which calculated every stat and then fed it to each statistic.
We could have broken it up, but to save 1 second of time only? For all that work? Surely there's a faster way.
- Move statistics out of the page
We've already done this as a little hack. We moved many important statistics from the /statistics page to the /overview page.
This improves loading because instead of loading every stat, we now only load important ones.
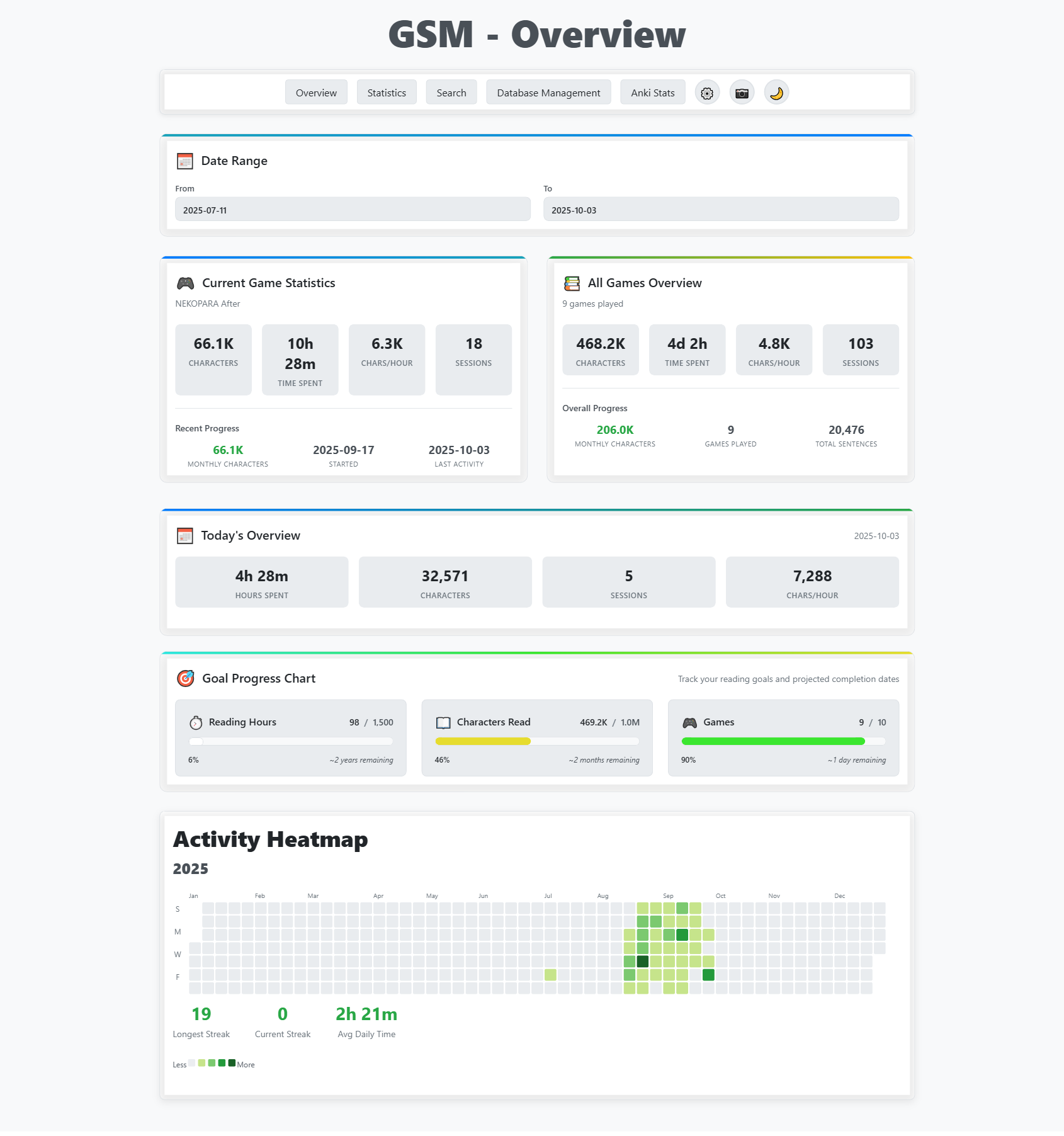
Obviously a hack... but it worked.... Load speed went from 7 seconds to 4... Still bad... 🤢
- Pre-calculate stats
Do we really need to calculate stats on the fly?
What if we were to pre-calculate all of our statistics and then present them to the user?
The final option, pre-calculating stats, is what we will be doing.
🥞 Rolling up stats
Every time GSM runs, let's pre-calculate all previous days stats for the user and then calculate just todays.
This will save us a lot of time.
Specifically our algorithm will now look like:
- When GSM runs, roll up all previous days stats to a table
- When we query statistics, use the pre-rolled up table for all previous data
- And then we calculate today's stats and add it to the rolled up stats
"Why calculate today's stats on the fly at all? Why not turn each game_line into a rolled up stats and add it to today's rollup?"
By Jove, a great question!
When GSM receives a line of text from a game it does a lot of processing to make it appear on screen etc, so why not precalculate stats there and then?
This makes a lot of sense!
BUTTTT.....
The absence of data is data!
Each game line looks exactly like this:
🗂 Entry ID: e726c5f5-7d59-11f0-b39e-645d86fdbc49
🕒 Timestamp: 2025-08-20 10:35:15
🔊 Audio: NEKOPARAvol.3_2025-08-20-10-35-28-515.opus
🖼 Screenshot: GSM 2025-08-20 10-35-15.avif
🦜 Game Line: "「もう1回、同じように……」"
📁 File Paths:
C:\XXX\AppData\Roaming\Anki2\User 1\collection.media\GSM 2025-08-20 10-35-15.avif
C:\XXX\AppData\Roaming\Anki2\User 1\collection.media\NEKOPARAvol.3_2025-08-20-10-35-28-515.opus
🧩 Original Game Name: NEKOPARA vol.3
🧠 Translation Source: NULL
🪶 Internal Ref ID: ebd4b051-27aa-4957-9b50-3495d1586ec1
📆 Epoch Timestamp: 1755648553.21247In the moment this imaginary rollup function only has this data.
When we calculate stats, we are looking at the past. We can see where the absences are to calculate the AFK time.
But in the moment, we don't know if the next game line will be 120 seconds or more later.
So therefore we cannot roll up today's stats because we cannot tell when a user takes an extended break away from the text or not.
What stats do we pre-calculate?
The next big question is "okay, what do we actually calculate?"
There's 2 types of stats:
- Raw stats like characters read
- Calculated stats that require more than just a single bit of data, like average characters per hour per a specific game.
I made an original list, booted up Claude and asked it to confirm my list and see if it thinks anything else is important.
Together we made this list:
_fields = [
'date', # str — date
'total_lines', # int — total number of lines read
'total_characters', # int — total number of characters read
'total_sessions', # int — number of reading sessions
'unique_games_played', # int — distinct games played
'total_reading_time_seconds', # float — total reading time (seconds)
'total_active_time_seconds', # float — total active reading time (seconds)
'longest_session_seconds', # float — longest session duration
'shortest_session_seconds', # float — shortest session duration
'average_session_seconds', # float — average session duration
'average_reading_speed_chars_per_hour', # float — average reading speed (chars/hour)
'peak_reading_speed_chars_per_hour', # float — fastest reading speed (chars/hour)
'games_completed', # int — number of games completed
'games_started', # int — number of games started
'anki_cards_created', # int — Anki cards generated
'lines_with_screenshots', # int — lines that include screenshots
'lines_with_audio', # int — lines that include audio
'lines_with_translations', # int — lines that include translations
'unique_kanji_seen', # int — unique kanji encountered
'kanji_frequency_data', # str — kanji frequency JSON
'hourly_activity_data', # str — hourly activity (JSON)
'hourly_reading_speed_data', # str — hourly reading speed (JSON)
'game_activity_data', # str — per-game activity (JSON)
'games_played_ids', # str — list of game IDs (JSON)
'max_chars_in_session', # int — most characters read in one session
'max_time_in_session_seconds', # float — longest single session (seconds)
'created_at', # float — record creation timestamp
'updated_at' # float — last update timestamp
]Then using this list we can calculate stats like:
- Average session length
- Reading time per game
- etc etc...
We don't need to calculate every single thing, just have enough data to calculate it all in the moment.
If we calculate things like total_active_time_seconds / total_sessions the abstraction becomes kinda too much.
Like come on, we don't need a whole database column just to divide two numbers 😂
In GSM you can also see your stats data in a date range:

So we have all these columns, and each row is 1 day of stats. That way we can easily calculate stats for any date range.
And we just need a special case for today to calculate today's stats.
How do we run this?
GSM is a Windows executable. Not a fully fledged server.
It could be ran every couple minutes, or ran once every couple months.
We need this code to successfully roll up stats regardless of when it runs, and we need it to be conservative in when it runs.
What we need is some kind of Cron system...
I added a new Database table called cron.
This table just stores information about tasks that GSM wants to run regularly.

We store some simple data:
- ID
- Name
- Description
- The last time it ran
- The next time it runs
- If it's enabled or not
- When the cron was created
- And the schedule it runs on
Then when we start GSM, it:
- Runs a query to get all cron jobs that needs to run now
SELECT * FROM {cls._table} WHERE enabled=1 AND next_run <= ? ORDER BY next_run ASCLoop through our list and run a basic if statement to see if one of our crons needs to run:
for cron in due_crons:
detail = {
'name': cron.name,
'description': cron.description,
'success': False,
'error': None
}
try:
if cron.name == 'jiten_sync':
from GameSentenceMiner.util.cron.jiten_update import update_all_jiten_games
result = update_all_jiten_games()
# Mark as successfully run
CronTable.just_ran(cron.id)
executed_count += 1
detail['success'] = True
detail['result'] = result
logger.info(f"✅ Successfully executed {cron.name}")
logger.info(f" Updated: {result['updated_games']}/{result['linked_games']} games")If it needs to run, we import that file (cron files are just python files we import and run. It's really simple)
We then run the command just_ran.
This command:
- sets
last_runto current time - calculates
next_runbased on the schedule type (weekly, monthly etc)
if cron.schedule == 'once':
# For one-time jobs, disable after running
cron.enabled = False
cron.next_run = now # Set to now since it won't run again
logger.debug(f"Cron job '{cron.name}' completed (one-time job) and has been disabled")
elif cron.schedule == 'daily':
next_run_dt = now_dt + timedelta(days=1)
cron.next_run = next_run_dt.timestamp()
logger.debug(f"Cron job '{cron.name}' completed, next run scheduled for {next_run_dt}")
elif cron.schedule == 'weekly':
next_run_dt = now_dt + timedelta(weeks=1)
cron.next_run = next_run_dt.timestamp()
logger.debug(f"Cron job '{cron.name}' completed, next run scheduled for {next_run_dt}")- Updates the Cron entry
This is just a super simple way to make GSM run tasks on a schedule without running every single time the app starts.
With all of these changes, our API speed is now....
- 6 seconds -> 0.5 seconds!
But the webpage itself still loads in 3.5 seconds.
Google Lighthouse
Google Lighthouse rates our website as a 37.
It complains about some simple things like:
- Preloading CSS / HTML
- No compression
- No caching
So what I did was:
- Set
rel=preloadfor important css - Added
flask-compressdependency to compress the Flask payload, using Brotli. I read this HN comment thread on Brotli vs zstd and I believe Brotli makes the most sense for now.
🤓 achtkually no! The
/api/stats endpoint returns a massive JSON payload containing all the stats (rolled up and todays) that's parsed by the frontend into pretty charts. Compressing it makes total sense.Also, GSM works on a network level too. You may wish to host it on a beefy computer and use something like Moonlight to play the game on your phone, and then look up stats on your phone too.
- Cached the CSS, since that changes very infrequently. Since GSM is not a server, users have to manually click "update" to update the app. At most this happens once every 3 days, so we use a 3 day cache here.
This led to our lighthouse score becoming 89, with the speed going from 3.5 seconds to 1.4 seconds.
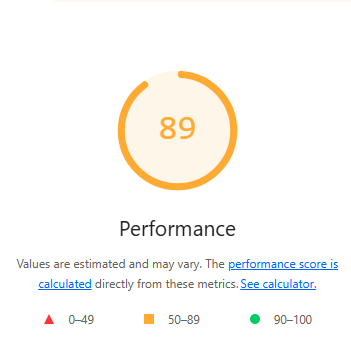
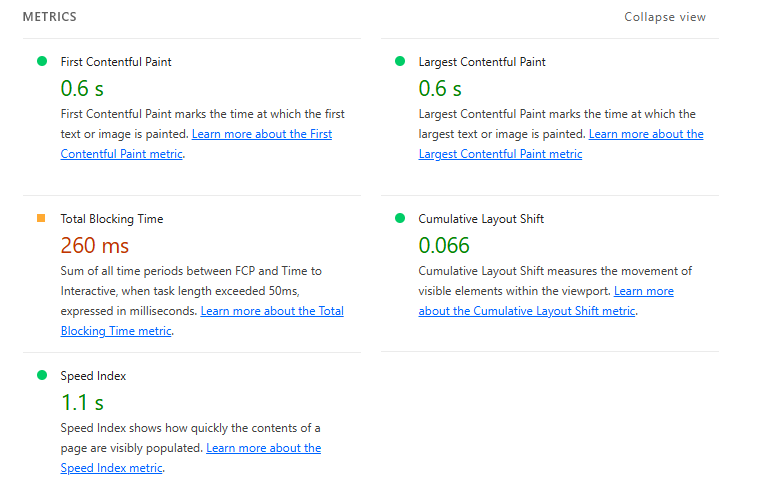
Very speedy!
Conclusion
We successfully doubled the loading speed of the statistics sites, but more importantly here are some key takeaways.
- The use of data is so vast, one persons "meh" data is another persons core product. We need to look at our data flow and our application to decide the best approach. For example, not rolling up today's stats to keep AFK metrics.
- There's a lot of arguments on Brotli vs zstd. For a local open source program either works.
- Lighthouse has become a lot more useful since I last used it back in 2018.