Timsort — the fastest sorting algorithm you’ve never heard of


Timsort: A very fast , O(n log n), stable sorting algorithm built for the real world — not constructed in academia.

Timsort is a sorting algorithm that is efficient for real-world data and not created in an academic laboratory. Tim Peters created Timsort for the Python programming language in 2001. Timsort first analyses the list it is trying to sort and then chooses an approach based on the analysis of the list.
Since the algorithm has been invented it has been used as the default sorting algorithm in Python, Java, the Android Platform, and in GNU Octave.
Timsort’s big O notation is O(n log n). To learn about Big O notation, read this.

Timsort’s sorting time is the same as Mergesort, which is faster than most of the other sorts you might know. Timsort actually makes use of Insertion sort and Mergesort, as you’ll see soon.
Peters designed Timsort to use already-ordered elements that exist in most real-world data sets. It calls these already-ordered elements “natural runs”. It iterates over the data collecting the elements into runs and simultaneously merging those runs together into one.
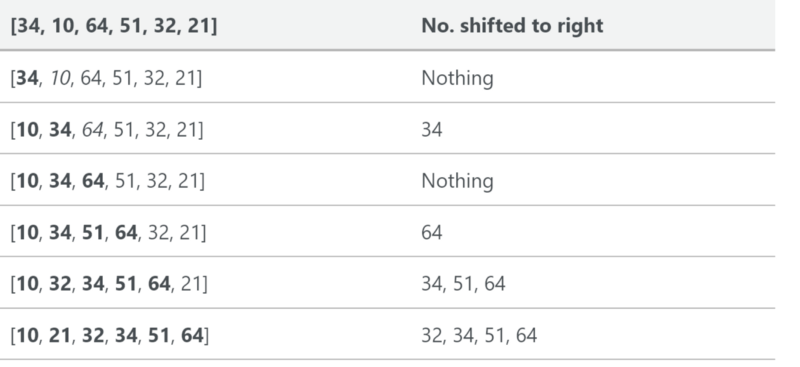
The array has fewer than 64 elements in it
If the array we are trying to sort has fewer than 64 elements in it, Timsort will execute an insertion sort.
An insertion sort is a simple sort which is most effective on small lists. It is quite slow at larger lists, but very fast with small lists. The idea of an insertion sort is as follows:
- Look at elements one by one
- Build up sorted list by inserting the element at the correct location
In this instance we are inserting the newly sorted elements into a new sub-array, which starts at the start of the array.
Here’s a gif showing insertion sort:
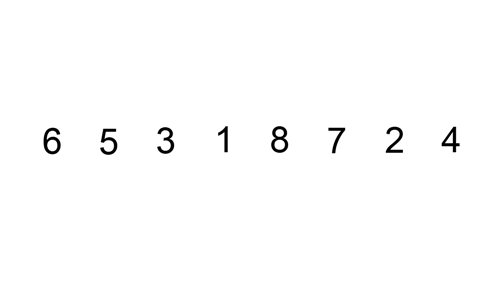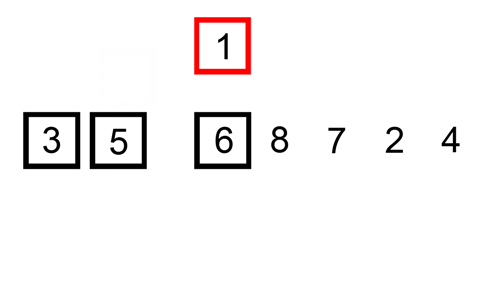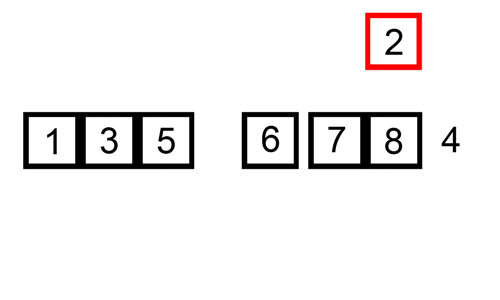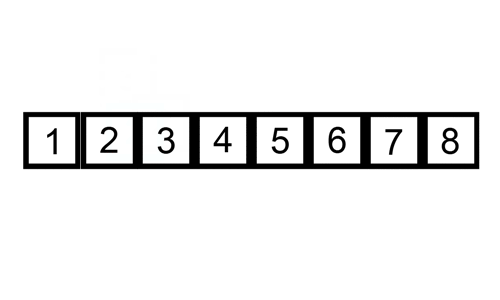
More about runs
If the list is larger than 64 elements than the algorithm will make a first pass through the list looking for parts that are strictly increasing or decreasing. If the part is decreasing, it will reverse that part.
So if the run is decreasing, it’ll look like this (where the run is in bold):

If not decreasing, it’ll look like this:

The minrun is a size which is determined based on the size of the array. The algorithm selects it so that most runs in a random array are, or become minrun, in length. Merging 2 arrays is more efficient when the number of runs is equal to, or slightly less than, a power of two. Timsort chooses minrun to try to ensure this efficiency, by making sure minrun is equal to or less than a power of two.
The algorithm chooses minrun from the range 32 to 64 inclusive. It chooses minrun such that the length of the original array, when divided by minrun, is equal to or slightly less than a power of two.
If the length of the run is less than minrun, you calculate the length of that run away from minrun. Using this new number, you grab that many items ahead of the run and perform an insertion sort to create a new run.
So if minrun is 63 and the length of the run is 33, you do 63–33 = 30. You then grab 30 elements from in front of the end of the run, so this is 30 items from run[33] and then perform an insertion sort to create a new run.
After this part has completed we should now have a bunch of sorted runs in a list.
Merging
Timsort now performs mergesort to merge the runs together. However, Timsort makes sure to maintain stability and merge balance whilst merge sorting.
To maintain stability we should not exchange 2 numbers of equal value. This not only keeps their original positions in the list but enables the algorithm to be faster. We will shortly discuss the merge balance.
As Timsort finds runs, it adds them to a stack. A simple stack would look like this:

Imagine a stack of plates. You cannot take plates from the bottom, so you have to take them from the top. The same is true about a stack.
Timsort tries to balance two competing needs when mergesort runs. On one hand, we would like to delay merging as long as possible in order to exploit patterns that may come up later. But we would like even more to do the merging as soon as possible to exploit the run that the run just found is still high in the memory hierarchy. We also can’t delay merging “too long” because it consumes memory to remember the runs that are still unmerged, and the stack has a fixed size.
To make sure we have this compromise, Timsort keeps track of the three most recent items on the stack and creates two laws that must hold true of those items:
- A > B + C
- B > C
Where A, B and C are the three most recent items on the stack.
In the words of Tim Peters himself:
What turned out to be a good compromise maintains two invariants on the stack entries, where A, B and C are the lengths of the three righmost not-yet merged slices
Usually, merging adjacent runs of different lengths in place is hard. What makes it even harder is that we have to maintain stability. To get around this, Timsort sets aside temporary memory. It places the smaller (calling both runs A and B) of the two runs into that temporary memory.
Galloping
While Timsort is merging A and B, it notices that one run has been “winning” many times in a row. If it turned out that the run A consisted of entirely smaller numbers than the run B then the run A would end up back in its original place. Merging the two runs would involve a lot of work to achieve nothing.
More often than not, data will have some preexisting internal structure. Timsort assumes that if a lot of run A’s values are lower than run B’s values, then it is likely that A will continue to have smaller values than B.
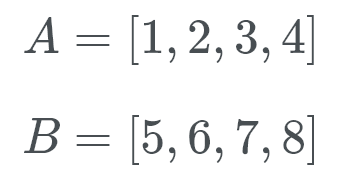
Image of 2 example runs, A and B. Runs have to be strictly increasing or decreasing, hence why these numbers were picked.
Timsort will then enter galloping mode. Instead of checking A[0] and B[0] against each other, Timsort performs a binary search for the appropriate position of b[0] in a[0]. This way, Timsort can move a whole section of A into place. Then Timsort searches for the appropriate location of A[0] in B. Timsort will then move a whole section of B can at once, and into place.
Let’s see this in action. Timsort checks B[0] (which is 5) and using a binary search it looks for the correct location in A.
Well, B[0] belongs at the back of the list of A. Now Timsort checks for A[0] (which is 1) in the correct location of B. So we’re looking to see where the number 1 goes. This number goes at the start of B. We now know that B belongs at the end of A and A belongs at the start of B.
It turns out, this operation is not worth it if the appropriate location for B[0] is very close to the beginning of A (or vice versa). so gallop mode quickly exits if it isn’t paying off. Additionally, Timsort takes note and makes it harder to enter gallop mode later by increasing the number of consecutive A-only or B-only wins required to enter. If gallop mode is paying off, Timsort makes it easier to reenter.
In short, Timsort does 2 things incredibly well:
- Great performance on arrays with preexisting internal structure
- Being able to maintain a stable sort
Previously, in order to achieve a stable sort, you’d have to zip the items in your list up with integers, and sort it as an array of tuples.
Code
If you’re not interested in the code, feel free to skip this part. There’s some more information below this section.
# based off of this code https://gist.github.com/nandajavarma/a3a6b62f34e74ec4c31674934327bbd3
# Brandon Skerritt
# https://skerritt.tech
def binary_search(the_array, item, start, end):
if start == end:
if the_array[start] > item:
return start
else:
return start + 1
if start > end:
return start
mid = round((start + end)/ 2)
if the_array[mid] < item:
return binary_search(the_array, item, mid + 1, end)
elif the_array[mid] > item:
return binary_search(the_array, item, start, mid - 1)
else:
return mid
"""
Insertion sort that timsort uses if the array size is small or if
the size of the "run" is small
"""
def insertion_sort(the_array):
l = len(the_array)
for index in range(1, l):
value = the_array[index]
pos = binary_search(the_array, value, 0, index - 1)
the_array = the_array[:pos] + [value] + the_array[pos:index] + the_array[index+1:]
return the_array
def merge(left, right):
"""Takes two sorted lists and returns a single sorted list by comparing the
elements one at a time.
[1, 2, 3, 4, 5, 6]
"""
if not left:
return right
if not right:
return left
if left[0] < right[0]:
return [left[0]] + merge(left[1:], right)
return [right[0]] + merge(left, right[1:])
def timsort(the_array):
runs, sorted_runs = [], []
length = len(the_array)
new_run = [the_array[0]]
# for every i in the range of 1 to length of array
for i in range(1, length):
# if i is at the end of the list
if i == length - 1:
new_run.append(the_array[i])
runs.append(new_run)
break
# if the i'th element of the array is less than the one before it
if the_array[i] < the_array[i-1]:
# if new_run is set to None (NULL)
if not new_run:
runs.append([the_array[i]])
new_run.append(the_array[i])
else:
runs.append(new_run)
new_run = []
# else if its equal to or more than
else:
new_run.append(the_array[i])
# for every item in runs, append it using insertion sort
for item in runs:
sorted_runs.append(insertion_sort(item))
# for every run in sorted_runs, merge them
sorted_array = []
for run in sorted_runs:
sorted_array = merge(sorted_array, run)
print(sorted_array)
timsort([2, 3, 1, 5, 6, 7])
The source code below is based on mine and Nanda Javarma’s work. The source code is not complete, nor is it similar to Python’s offical sorted() source code. This is just a dumbed-down Timsort I implemented to get a general feel of Timsort. If you want to see Timsort’s original source code in all its glory, check it out here. Timsort is offically implemented in C, not Python.
Timsort is actually built right into Python, so this code only serves as an explainer. To use Timsort simply write:
list.sort()
Or
sorted(list)
If you want to master how Timsort works and get a feel for it, I highly suggest you try to implement it yourself!
This article is based on Tim Peters’ original introduction to Timsort, found here.