Over-engineering my backups


2 years ago I wrote about how I over-complicated my document storage system:

I wrote about backups too, but it wasn't serious.
Now, let's get serious about backups and back the ups more than the backs have ever upped!
Please note that I do not entirely know what I'm doing from the start. If you follow this article you will see my research in real time and understand why I'm doing things.
And you'll probably learn a significant amount about encryption, compression, and general DevOps stuff. My full time job is as an infrastructure & security dev, so yeah. Be prepared to get nerdy 🤓
What do I want?
I want a system that:
- Enables encryption
- Protects against bitrot or third party attacks on my backups
- Is automated
- Compression
- Uses cool enough tech so that I can talk about it on my CV
I originally used a shell script in my Paperless blog.
I looked at using a Python script now.
Can we use something that already exists? We can!
Meet Restic.
Restic is a backup tool that enables us to do all of the above.
Restic is newer technology and I love learning about new things. I have used BorgBackup etc before. Let's try something new 😄
Let's get started
Restic First Steps
Restic firstly backups your files in terms of archives, rather than big zip files.
So previously I imagined backups as:
- Zip all the contents
- Store the zip somewhere
Restic does it like:
- Store all the contents into an archive, which behaves like a USB stick
- Store that archive somewhere
This is a bit different. Archives in Restic do not re-save files.
So imagine this:
$ ls
test1.txt test2.txtYou then zip this:
$ zip *Your zip now contains both files. Let's say in the future you change test1.txt and zip it up.
Now you 2 zips. The first zip contains the old test1.txt and test2.txt. The new zip contains the new test1.txt BUT it also contains the old test2.txt.
Zip files duplicate needlessly.
Archives, on the other hand, only update the files that have changed.
When you take a backup of an archive, it's called a "snapshot". A snapshot is an image of your files at a particular moment in time.
If we take 2 snapshots, snapshot1 will feature both files, and snapshot2 will feature the changed file and a bit of text that says "oh yeah test2.txt is included here too". This means we don't duplicate files across snapshots!
Okay, so once Restic is installed you need to initialise an archive. You can do so locally with:
restic init --repo .This says "initialise an archive in the current folder".
This makes a bunch of folders in our current folder:
drwx------ - bee 26 Oct 14:53 data
drwx------ - bee 26 Oct 14:53 index
drwx------ - bee 26 Oct 14:53 keys
drwx------ - bee 26 Oct 14:53 locks
drwx------ - bee 26 Oct 14:53 snapshots
.r-------- 155 bee 26 Oct 14:53 configInteresting! What do each of these do?
- Data = The actual backup data. The data is divided into small chunky blobs, and this folder contains those blobs.
- Keys = The cryptographic keys used for encrypting and decrypting the data. Restic is encrypted by default 🥳 And Flippo Valsorda says its good (they are a famous cryptographer)
- Locks = Controls concurrent access to the data.
- Snapshots = Contains metadata about the snapshots that have been created. Each snapshot is its own directory, which stores info about the files.
- Index = Maps the blobs to the snapshots.
- Config = Stores configuration settings for the respository.
And now to backup all you need to run is:
restic --repo /tmp/backup backup ~/Documents🥳
Why you should not use Restic
Okay, now you have a good idea of what Restic does, let's talk about its downsides.
- Files are turned into blobs, not stored raw.
If Restic was to break somehow, perhaps you wouldn't be able to restore your files since Restic turns them into blobs. You can use Restic's verify to make sure it still works, but this is still a risk.
- One backup to multiple locations is not really supported
In the 3-2-1 backup plan I talked about earlier, we want to make one backup to multiple places. Let's say we want to back up to Google Drive and S3.
The way to do this in Restic is either:
- Initialise 2 repositories. One on S3 and 1 on Google Drive.
- Create 1 repository locally (or in S3) and copy that across.
(1) is bad because we are repeating CPU cycles. Restic compresses and encrypts the data twice, because there is 2 repositories.
(2) is bad because we either have to create a repository locally (so if you want to backup X amount of data, now you have 2X amount of data locally) or copy it across cloud providers (which is slow and could cost us some money in egress fees).
You can copy Restic repositories using Restic Copy, but the above problem still exists. It would be nice to be able to say "backup to S3 AND ICloud at the same time" instead of juggling repositories and copying them.
For me personally I want a sporadic backup to an external HDD and a constant backup to the cloud. I can't really copy across so easily and I don't want to spend much in egress fees :(
- It is complicated
Restic is fundaementally a CLI tool and pretty much everyone that uses it will write their own backup scripts.
To fix this you can use Backrest:
 garethgeorge
garethgeorgeWhy you should use Restic
If you are still reading this, perhaps you are wondering why Restic over the zip-folder method previously mentioned.
- Deduplication is built in
Restic automatically deduplicates files, so if you have the same file in 2 places it will not be copied twice.
- Archives do not duplicate files needlessly
Before my backup strat was to use zip to backup everything. This meant I had the same file multiple times in each zip.
This cost me a lot of £££ and wasted storage.
Archives in Restic never store the same file twice, so you can have multiple snapshots of your system with changes but you do not duplicate the files.
- Compression built in
Restic has built-in compression which reduces the backup size.
- Encryption is good
“The design might not be perfect, but it’s good. Encryption is a first-class feature, the implementation looks sane and I guess the deduplication trade-off is worth it. So… I’m going to use restic for my personal backups.” Filippo Valsorda
This guy is head of cryptography for the Go language at Google and is basically a deity for cryptographers.
He is also European, and from what I know (being European myself) when someone says something is "good" it means its very very good. So I'm inclined to believe him.
- This will look good on your resume (CV)
As my company is doing layoffs for the second time this year I need to sharpen my skills again.
 Zack Whittaker
Zack WhittakerAccording to this totally legit website at least 8 companies use Restic, which bodes well because only 4 use Borg.
- Partial backups are possible
Using the zip file talked about before, you'd have to backup all in one go.
Make zip. Upload it. You can't stop halfway through and resume another day.
With Restic, you can! If you are backing up to a USB and decide to stop, you can just stop and resume later.
Backrest
Let's try the Backrest Docker webapp.
Here's my Docker compose file. It will create all of its config in the current file
version: "3.2"
services:
backrest:
image: garethgeorge/backrest:latest
container_name: backrest
hostname: backrest
volumes:
- ./backrest/data:/data
- ./backrest/config:/config
- ./backrest/cache:/cache
environment:
- BACKREST_DATA=./backrest/data # path for backrest data. restic binary and the database are placed here.
- BACKREST_CONFIG=./backrest/config/config.json # path for the backrest config file.
- XDG_CACHE_HOME=./backrest/cache # path for the restic cache which greatly improves performance.
- TZ=Europe/London # set the timezone for the container, used as the timezone for cron jobs.
restart: unless-stopped
ports:
- 9898:9898docker compose up and go to localhost:9898 and you'll see this.
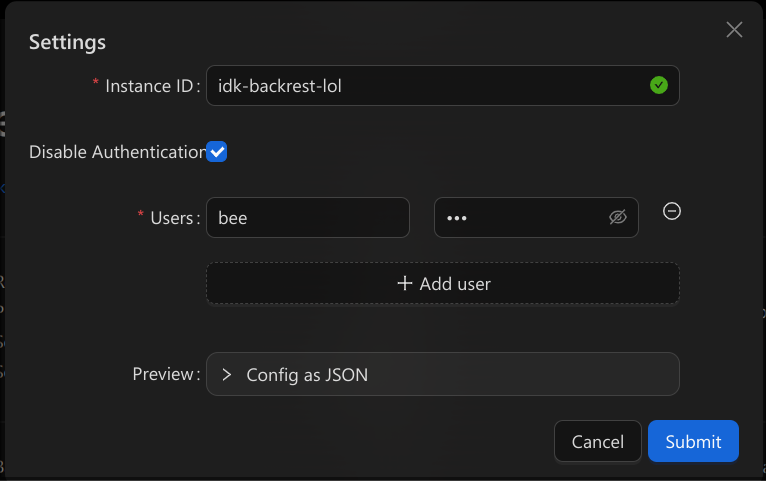
Fill it out idk what instance ID is either by the way, probably don't need to google it
If you have simple backup needs I think the WebUI is good.
But this is "over-engineering". It wouldn't be over-engineering if I used a WebUI!
I have some mega stupid requirements for my backups:
- The external HDD will not be plugged in 24/7. It needs to backup when it is plugged in.
- I will not have internet 24/7, it will need to backup when there's internet.
- I want to backup Docker containers, but not the containers themselves. I will run the respective apps backup functions and store that. This requires some scripting.
So read on if you want to learn more about Restic in-depth, otherwise you are welcome to step off the ride and enjoy Backrest.

The Red Pill - Using the Restic CLI
Sorry if this annoys you, but there are some out there who would love to get more into DevOps and seeing the thought process of an actual DevOps girlie might be helpful :)
Okay, so we know with Restic we need a repository.
To make a repository we need to know where we're going to back up to.
Evaluating our options
Not only am I an engineer, I am unfortunately also British.
Thanks to years of British Austerity I am now afraid to spend any more money than I have to.
This means, yes, I will do the maths to work out the cheapest way to backup everything and be safe.
Firstly, let's get the obvious one out of the way.
The external HDD.
I picked this up:
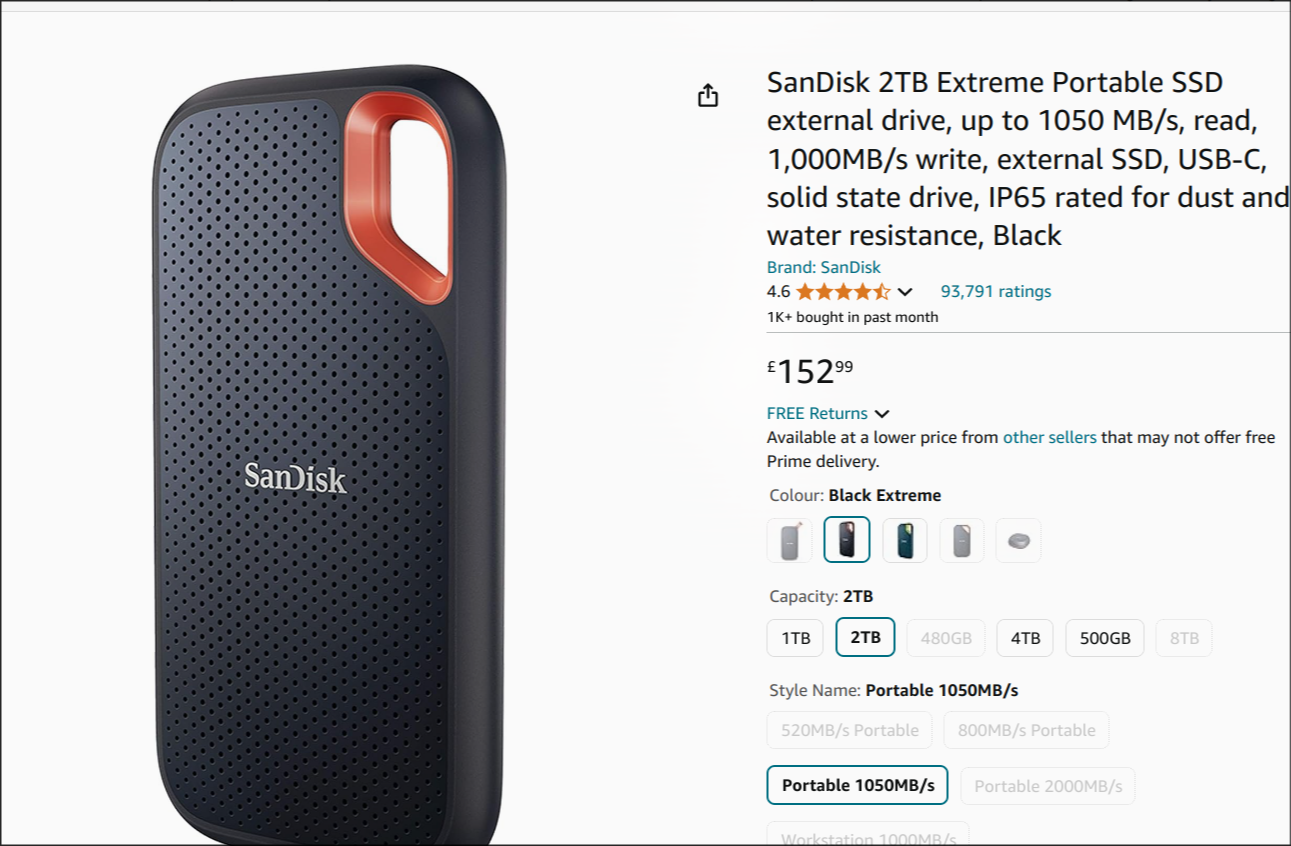
£150 for 2tb in an external SSD. Pretty good. And at 1gbp/s speed that means that I can backup 1tb in 1 and a half hours.
Now let's look at ✨cloud✨ options.
Restic officially supports these protocols:
- SFTP
- Local (so if you mount Google Drive or something, you can save it locally and have Drive upload it)
- REST Servers
- S3 and any S3 compatible services
- Anything rclone supports.
Okay so for things like Google Drive etc where it's mounted, you will have 2X amount of storage used because it has to write locally. I am trying to avoid that.
If you would like to use a normal Cloud drive service, here's a massive spreadsheet comparing them all:

I actually have too many cloud drives I'm paying for, my hope is to move everything to a local machine and just have great backups to save some money.
Realistically I do not use Cloud Drives for anything other than backups 😄
I think my best bet is probably S3 compatible services.
In terms of services, I am thinking of:
- Backblaze B2
- S3 Deep Glacial Archive
- Normal S3
- rsync.net (not S3, but similar enough and is well-loved by people online)
Next up, let's set out some parameters.
- I do not plan to access the backups often
- I will probably store around 2tb
- I will write once a month.
Let's look at rsync.net first.
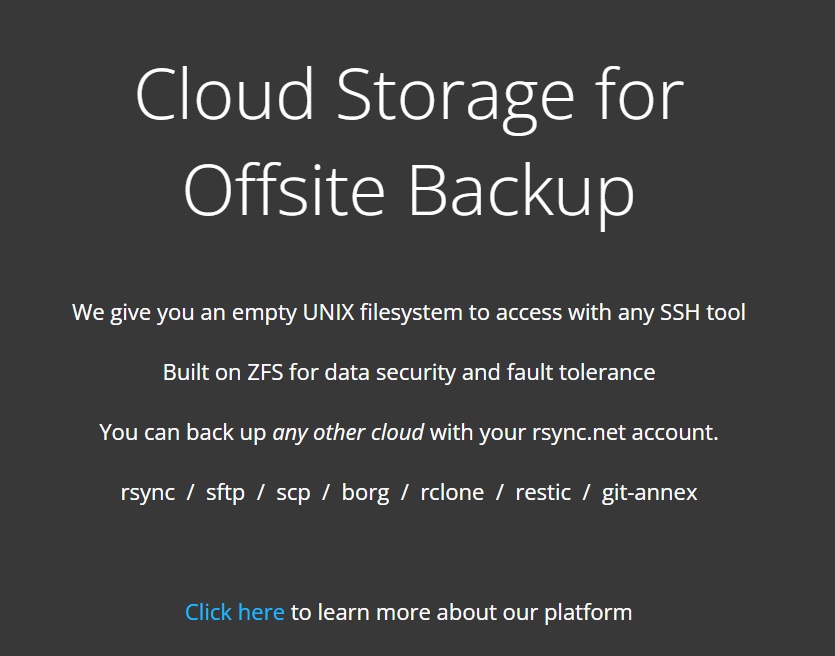
The premise is cool. I want storage. Not much else. Give me a box I can get to with SSH!
They claim to have "simple pricing":

But as I live in one of the 195 countries that aren't the United States of America, I have absolutely no idea what a "cent" is. They do not even use a currency symbol here, so I'm also unsure whether it's USD or some other currency.
I can just tell that as a Liverpudlian I am probably going to have a bad experience if they can't even tell me what currency the product uses or what a "cent" is. Very r/USdefaultism here.
Let's look at S3 Deep Glacier Archives, which is a really cheap S3 storage option.
Let's say after 1 day I transfer my data from S3 to GDA (you need to set a rule up to use it).
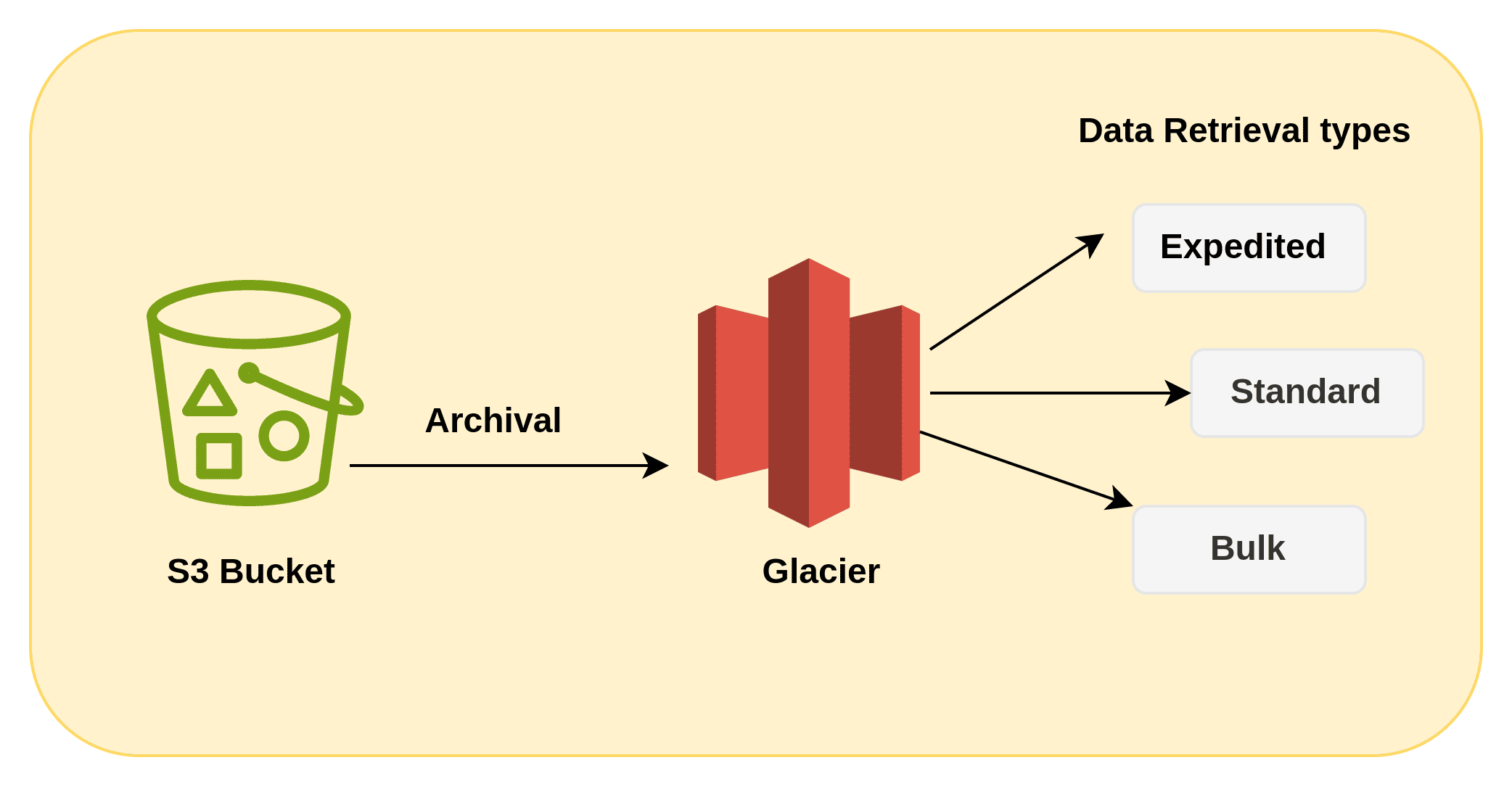
- I upload to S3 standard, which costs:
- $0.023 per GB-month (prorated)
- $0.005 per 1000 files uploaded
- After one day, the files are transitioned to the GDA tier:
- $0.00099 per GB-month (prorated)
- $0.05 per 1000 files transferred
A Restic blob has a max size of 8mb, and a min-size of 512kb.
We'll say our average blob size is 4mb.
So for 2tb we'll have 500k files that are each 4mb.
Unlike zips which count as one file, Restic archives count as many files as it's broken down into these blobs.
In Standard S3 this will cost:
- £46 per month for 2tb storage (£0.023 * 2000)
- £25k for 500k files (£0.05 * 500k)

Only £25k to backup some files.
I can see why people use cloud drives now.
Please donate to me so I can afford to make backups k thanks

Also I knew before writing this that the egress of glacial archives was going to be the worst part. For reference it would cost around £50k+ to just restore from backup there. lmao.
Okay, let's skip S3 and look at Backblaze B2.
Backblaze B2 is an S3 compatible cloud storage.
Let's do the maths again. Thankfully they have a calculation in their website.

Wow, $144 per year! Okay, but what about egress? How much does it cost to restore?

FREE!?!?!!
Okay, what about number of files transferred?
So they charge per API call, and one of their APIs is "upload file" to allow us to upload done file.
This is worrisome 🥴 I reckon this is where it will cost the most!

FREE!?!?! AGAIN!?!?!?!
What is wrong with them???
On top of this... You only pay for what you use.
With Google Drive etc you pay for 2tb. If you only use 10gb, you pay for 2tb.
With Backblaze B2 you only pay $12 per month if you use the whole 2tb, otherwise it's cheaper.
This is crazy.
They also have unlimited data backups for just $99 per year:


But this is Windows only and you have to use their specific application.
Backup conclusions
Okay, so my plan is:
- Use Restic to backup to 2 different locations
- A local SSD that is only sometimes plugged in
- Backblaze B2 when I have internet
Let's actually do this by writing some code and exploring Restic in-depth.
Setting up the local hard drive
I plug this thing in and run a simple little fdisk
$ sudo fdisk -l
Disk /dev/sda: 1.82 TiB, 2000365371904 bytes, 3906963617 sectors
Disk model: Extreme 55AE
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 1048576 bytes
Disklabel type: gpt
Disk identifier: 2D5CD6D0-FE65-4259-86DC-3BEDB545DBBBNow we need to make a mount point.
I have learnt that not mounting stuff into my home directory ends up with permissions errors that I'm too lazy to fix.
So I do:
$ mkdir /mnt/portable_ssd
$ mount /dev/sda ~/mount_ssd
mount: /mnt/portable_ssd wrong fs type, bad option, bad superblock on /dev/sda, missing codepage or helper program, or other error.
dmesg(1) may have more information after failed mount system call.That's annoying. I expected that to work. Looks like my SSD is mounted at /run/media/bee/6E09-F0FC though according to Thunar.
Let's make a new repo quickly:
/run/media/bee/6E09-F0FC
❯ restic init --repo .
enter password for new repository:
enter password again:
created restic repository 6f53fade2a at .
Please note that knowledge of your password is required to access
the repository. Losing your password means that your data is
irrecoverably lost.Okay cool.
Now we have a repo, and we have data to backup.
What I want to do is everytime I plug this little thang in I want to run a backup script.
You can do this in Linux using udev rules. There's a Python library and Borg Backup has a shell script you can copy.
Let's fix our mounting issue. Let's tell Linux to auto-mount it everytime I plug it in.
To do this, we need to use /etc/fstab!
Run sudo blkid /dev/sda1 to grab the UUID and some other info.
Now sudo vim /etc/fstab and add the correct line. Read this for a guide on /etc/fstab or just use your favourite chat AI application to write the rule for you 🤷
UUID=6E09-F0FC /mnt/portable_ssd exfat defaults,noauto,x-systemd.automount 0 0In order for udev to run a script when we plug something in, we need a script to run.
Let's work on that :)
Setting up our CLI tool
I want a Python CLI tool. I imagine it to have arguments like --backup_to_ssd --backup_to_backblaze --generate_backups_from_docker etc.
Let's use uv to make a little project.
❯ uv init --name baccy --package .
Initialized project `baccy` at `/home/bee/Documents/src/baccy`
# --package means "this is a cli tool" which means we can run uv run baccy to run this :)It also enables me to turn this into a true cli tool that I can call like
backups instead of python3 backups.pyAlso my company is doing layoffs and I need to brush up on my skills.
uv is a cool new Python project manager 😅That was easy!
I want to use click as an argparser, so let's add that quickly:
❯ uv add click
Using CPython 3.12.7 interpreter at: /usr/bin/python
Creating virtual environment at: .venv
Resolved 3 packages in 169ms
Prepared 1 package in 49ms
Installed 1 package in 1ms
+ click==8.1.7
Now we add a main.py and write this in it:
#!/usr/bin/env python3
import sys
try:
with open("/tmp/udev_test.log", "a") as log:
log.write("Hello\n")
except Exception as e:
with open("/tmp/udev_error.log", "a") as error_log:
error_log.write(f"Error: {e}\n")
This is so I can run it as ./main.py :)
We can write the rest of it later!
Back to udev and setting up the SSD
Let's get the ID of our SSD:
❯ lsblk --fs -o +PTUUID /dev/sda
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS PTUUID
sda 2d5cd6d0-fe65-4259-86dc-3bedb545dbbb
└─sda1 exfat 1.0 6E09-F0FC 2d5cd6d0-fe65-4259-86dc-3bedb545dbbbNow we make the udev rule.
sudo vim /etc/udev/rules.d/99-portable-ssd.rules
udev rules are processed according to the number. so 1-* will be processed first. Our rule 99- will be processed as the last rule.
Now we make our rule:
SUBSYSTEM=="block", ENV{ID_PART_TABLE_UUID}=="2d5cd6d0-fe65-4259-86dc-3bedb545dbbb", RUN+="/home/bee/Documents/src/baccy/src/baccy/main.py"
i agree calling main.py is messy, but i am too lazy to make it a real package. I shoulda wrote this in Rust
- SUBSYSTEM=="block": Ensures this rule only applies to block devices.
- ENV{ID_PART_TABLE_UUID}: Matches the partition table UUID (
PTUUID) of the device. - RUN+=: Specifies the script to run when the rule is triggered.
After creating the rules, reload udev.
sudo udevadm control --reload
sudo udevadm trigger
Now we test. Plug in our SSD again.
wOO! it works!
❯ cat /tmp/udev_test.log
Hello
Hello
Hello
Hello

Okay, now we have our udev rule. Let's go back to.....
Writing our backup script, part 2
Okay so I want 2 functions:
- Run Restic backup to SSD. Takes a file path as input, and runs
restic backup - Create paperless backup (using docker exec) and call (1) with the file path
And (2) should be a command like argument, so we can do main.py --backup-paperless.
And we'll need some helper functions like:
- Alert me if the backup goes right or wrong
- Check if the previous backups are okay
First, we need a Restic backup command. I think this would work:
restic -r /mnt/portable_ssd/ backup --compression auto -p password.txt {path}restic -r /mnt/portable_ssd/ backup --compression auto -p password.txt /home/bee/Documents/src/paperless/export/paperlesss_export.zip
repository 6f53fade opened (version 2, compression level auto)
created new cache in /home/bee/.cache/restic
Save(<lock/ba31c913cb>) failed: open /mnt/portable_ssd/locks/ba31c913cbcfceb765d5238bf329816e5ce1a89d5f57fb7a1c2754ddb1ee6870-tmp-2155058137: permission denied
unable to create lock in backend: open /mnt/portable_ssd/locks/ba31c913cbcfceb765d5238bf329816e5ce1a89d5f57fb7a1c2754ddb1ee6870-tmp-2155058137: permission deniedNow I get this error.
Turns out you need to unlock a repo before using it:
❯ restic unlock -p password.txt -r /mnt/portable_ssd/
repository 6f53fade opened (version 2, compression level auto)But that didn't work either!
Now interestingly it works in /tmp
❯ restic -r /tmp/tmp backup --compression auto -p password.txt /home/bee/Documents/src/paperless/export/paperlesss_export.zip
repository fc7697b9 opened (version 2, compression level auto)
created new cache in /home/bee/.cache/restic
no parent snapshot found, will read all files
[0:00] 0 index files loaded
Files: 1 new, 0 changed, 0 unmodified
Dirs: 6 new, 0 changed, 0 unmodified
Added to the repository: 1.025 GiB (1.023 GiB stored)
processed 1 files, 1.028 GiB in 0:02
snapshot ce5a9285 savedI am thinking that mounting in /mnt/ results in permissions errors, possibly because exfat does not have nice permissions on Linux.
Let me try mounting it as my user:
UUID=6E09-F0FC /mnt/portable_ssd exfat defaults,noauto,x-systemd.automount,uid=1000,gid=1000 0 0into /etc/fstab.
This worked! By adding uid=1000,gid=1000 I convinced Linux my user owns it, and I can run restic backup on it 🥳
Okay, just because I can run it doesn't mean udev can run it. Let's try using udev!
1 hour later
Hmmm.. I can mount just fine. And I can run the cli tool manually just fine. But I'm not sure why udev won't work 🤔
It runs a small shell script, and the start of my Python script runs (because I make it write to a file as a test) but the rest of it doesn't... It gets killed? I think??
6 hours later
Okay, turns out my backup script either takes too long to run and udev kills it, or it starts too early before the ssd is ready.
The solution to this is with Systemd 🥳
In my systemd files I have this:
/etc/systemd/system
❯ sudo cat automatic-backup.service
[Unit]
Description=backup to ssd
[Service]
Type=simple
User=bee
Group=bee
TimeoutStartSec=0
RemainAfterExit=no
ExecStart=/home/bee/Documents/src/baccy/src/baccy/main.py
[Install]
WantedBy=multi-user.targetThis just tells it to run the main.py program like before, then I did systemctl enable automatic-backup.service.
Then in udev I have this:
ACTION=="add", SUBSYSTEM=="block", ENV{ID_PART_TABLE_UUID}=="2d5cd6d0-fe65-4259-86dc-3bedb545dbbb", TAG+="systemd", ENV{SYSTEMD_WANTS}="automatic-backup.service"Which says "run my systemd service".
So instead of udev running the script, I am off-loading it to systemd which works fine and now actually does work anytime I plug my ssd in 🥳!!
systemd. gonna be honest i dont care for drama and I use whatever works. i dont even know why they dont like it 🤷My next plan is to:
- Enable cleanup of old snapshots
- Add support for Backblaze b2
- Add checks to make sure snapshots are okay
- Add alerting to let me know if a backup has failed or succeeded
- Tell btrfs to not backup my backups lol
Setting up Backblaze
Okay so I've made an account. Now let's make a bucket!
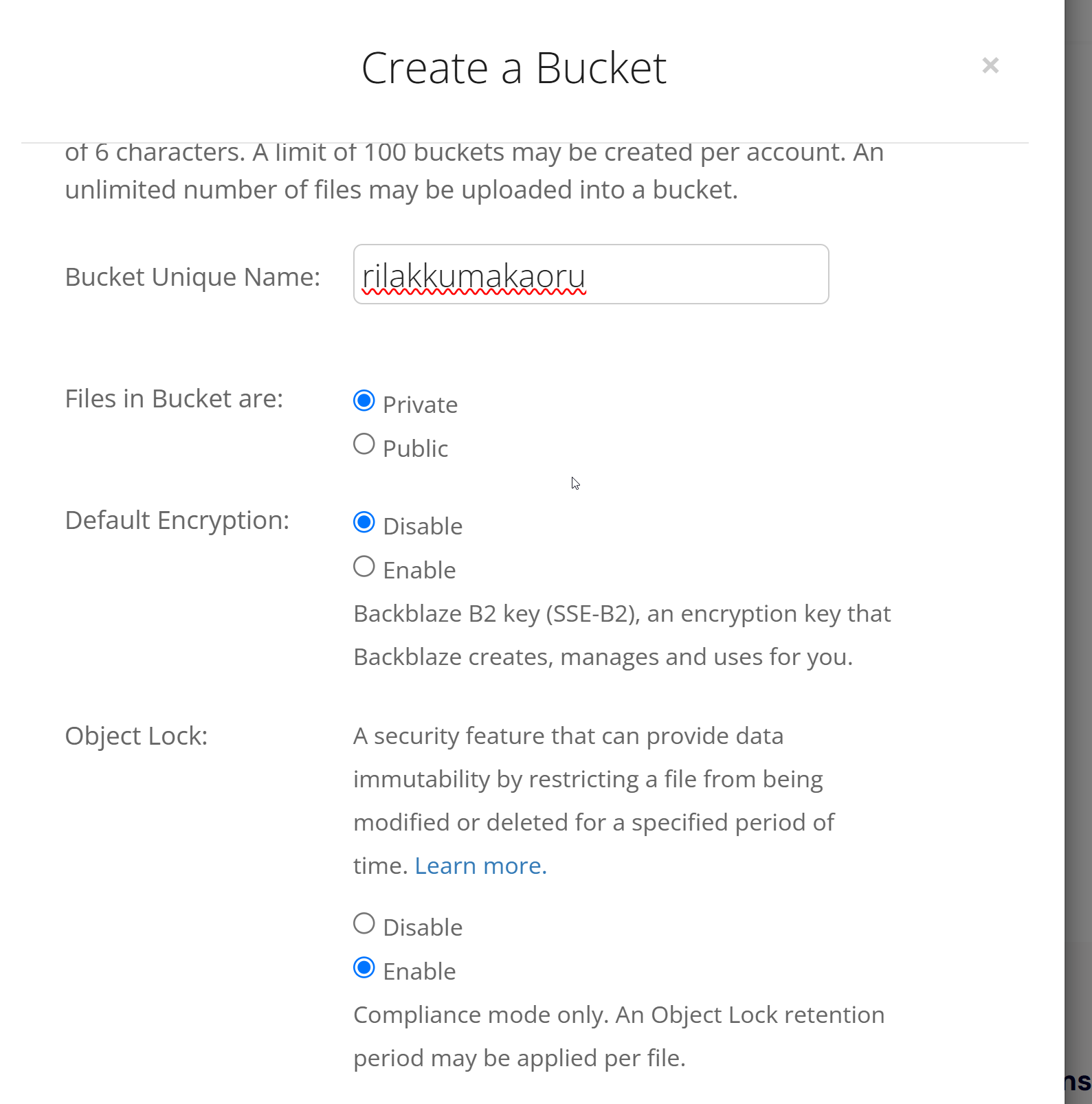
Bucket names are globally unique and while not a secret, you probably do not want to point out what buckets you own. So be careful sharing them :)
There are many cool hacks you can do with just a bucket name. As an example from AWS-land, you can be forced to spend £100,000 if someone just knows your bucket name:
S3 is a service provided by Amazon (AWS), and it's such a good idea that many other companies make tools similar to S3 and use the same API for it. Backblaze is one (but also see Cloudflare, Wasabi, and even Mega).
Encryption? Do we need encryption if Restic encrypts already?
It says Backblaze manages the key for us, so we never have to think about it. We can still use B2 like normal whether we encrypt it or not via Backblaze.
But then, what's the point?
- Backblaze knows our key. A rogue employee could decrypt our data.
- The API does not need a key - if our keys are leaked someone can access our data without fighting the encryption.
There are 3 good reasons and 1 bad reason I see to this:
Bad
- It's possibly slower than not using Backblaze encryption edit: I don't think this is true. Backblaze says it's server side encryption. You send it raw to Backblaze, probably stored in RAM, encrypted and then written.
Good
- If someone was to break into Backblaze and steal a hard drive, they can't read our data.
- Some Governments can compel Backblaze for data, but there are certain rules that make forcing Backblaze to decrypt it harder.
- It's a free feature and we do not have to worry about anything
Therefore, why not enable it? There is no harm, and while the "good list" is not very large at least it exists 🤷♀️ Also, Restic encrypts our data. 2 forms of encryption is always going to be better than 1 form, no matter how bad the 2nd form is 🐶
Object Locks
Append-only backups are all the rage these days.
My friend works as an emergency & disaster consultant for many tech companies.
She tells me that when they experience a ransomware attack, they do not know if the virus is in the backups or not. It could have been written to a backup and laid dormant, only to reactivate (this has happened before).
Or it could edit previous backups to exist in all of them....
Append-only backups say "you can not edit this backup after it's made". You create a backup, a snapshot and that's it. No editing!
Restic supports this, but also so does B2.
You can use object locks (another famous S3 feature) to control files being modified or deleted.
The only issue is that Restic may have issues cleaning up old backups... Unless we time it well.
So we could say to Restic "delete backups older than 1 month", and to Backblaze we can say "do not let us edit or delete backups until they are 28 days old".
Firstly, let's take a quick detour.
NCSC Guidance on Backups
The NCSC (the UK's cybersecurity government body for businesses) has some great advice on protecting backups here:

We can implement some of these rules right now!
TL;DR for our usecase:
Backups should be resllient to destructive actions
- We shouldn't be able to easily delete them
- When deleting backups, waiting longer to delete them is always better
- We should be able to restore from backups, even if later versions become corrupted
- Our backups should be read-only, so attackers can't alter them after the fact
- Store backups according to a fixed time, rather than a number.
- Restic lets us say "only store 10 backups" which is bad. An attacker can easily run the backup script 10 times to get rid of all of our "safe" backups and replace them with corrupted backups
- Instead we should only clean up backups older than a certain date & time.
- We should have versioned backups (Restic does this with snapshots)
- Robust key management
- Our Restic password must be accessible without the use of a computer
- NCSC suggests writing it down and storing it in a safe
- Alerts are triggered if significant changes are made
- If our backup schedule is broken, we should alert.
- If backups fail, we should be alert.
- If a lot of backups are made, perhaps an attacker is trying to force corrupted backups into our mix and we should alert.
And one more thing not mentioned:
- Our backups should be secure.
- For the local SSD we need to encrypt it.
- Our our cloud, we should secure access to it
Securing Backblaze B2
Because Restic repositories are their own thing, I can't tell Backblaze to delete old files.
So what I would like to do is this:
- Restic manages its own snapshots & cleanups
- Because Restic manages this, this means our user will need permission to delete files
- If our user can delete files, an attacker can too
- Restic should not use hard-delete, but instead soft-delete (hide files)
- Backblaze should store file versions so even if something is soft-deleted, it's not truly deleted.
- After X days, Backblaze hard-deletes all soft-deleted files
This way even though our user can "delete" things, it is not truly gone.
Let's see if this is possible in Backblaze.
The S3 API uses the same endpoint for both deletion and hiding of files:
In the IAM world we can restrict access to an endpoint, but restricting access to actions on an endpoint is weirder and probably not supported....
The native B2 API supports this, but Restic says it doesn't like it right now.
On the subreddit a Backblaze employee talks more about IAM rules & soft deletes in regards to both the API and the WebUI
Comment
byu/r0ck0 from discussion
inbackblaze
TL;DR what we want to do is not possible with Backblaze 🫠
I also cannot really find any IAM serivces on Backblaze, unlike AWS. So looks like we're stuck here.
Restic has some support here though for append only backups:
But it says "use either REST or rclone backends", and we want to use an S3 backend cause I can't really be bothered with the others.
My worry here is that if an attacker has physical access to my machine, that means they can:
- Delete my backups from my SSD
- Use the API keys to delete my online backups
- ???
- Profit
But! We can do a bit of threat modelling here to better understand my situation.
Basic Threat Modelling of our Backups
Okay, so some basic questions to ask here:
- What do we want to protect?
- Who is our attacker?
- What appropriate measures can we take to protect against this attacker?
We want to answer the question "what is our worst case scenario"? s
What do we want to protect?
My computer has a lot of personal data on it, and I'd want to make sure I don't lose it.
Who is our attacker?
Someone breaks into my home and steals my computer.
Someone steals my computer and uses my data to blackmail me.
My computer dies.
I get ransomware'd
What appropriate measures can we take?
- We can make 3-2-1 backups (hey! it's this article!)
- We can encrypt our hard-drive and backups
- I can be wary of any links I click on, use a stupid operating system (arch linux), and ensure my backups are not super easy to access
- I can do the above by only plugging in my SSD sometimes, and not mounting my cloud drive
- I doubt ransomware will find an S3 API key and start making requests to it. If I was to be hit by ransomware, it will just be a broad-attack and nothing super specific or smart. In fact, I doubt it would even run on Linux.
And that's it.
We don't really need super advanced lifecycle policies to protect against these things.
Many people in security often over-optimise their security before trying to understand who they're protecting themselves against.
It's really important to take a step back and ask:
"What are we doing, and why are we doing it?"
Every once in a while.
B2 Setup Continuation
After making our bucket, let's make some keys for it.
On the left click "application keys" and make a new set of keys.
Export these keys and make a new repo like below:
~
❯ export AWS_ACCESS_KEY_ID=XXXX
~
❯ export AWS_SECRET_ACCESS_KEY=XXXXX
~ 9s
❯ restic -r s3:{bucket URL}/{BUCKET NAME} init
enter password for new repository:
enter password again:
created restic repository 02d2ff9e80 at s3:XXXXX
Please note that knowledge of your password is required to access
the repository. Losing your password means that your data is
irrecoverably lost.
~Your {bucket URL} can be found on the bucket itself, and {BUCKET NAME} is just the name of the bucket.
Okay, now we've made the repo let's just copy our command to our code.
#!/usr/bin/env python3
import subprocess
import logging
import sys
import click
# Configure logging for journalctl output
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger = logging.getLogger()
@click.command()
@click.option("--ssd", help="Runs the ssd backup commands", is_flag=True)
@click.option("--backblaze", help="backsup to backblaze", is_flag=True)
def main(ssd, backblaze):
if ssd:
logger.info("SSD backup has been chosen")
restic_backup_ssd()
if backblaze:
logger.info("Backblaze backup has been chosen")
restic_backup_backblaze()
logger.info("Backup process completed.")
def create_paperless_backup():
try:
result = subprocess.run(
[
"docker",
"exec",
"paperless",
"document_exporter",
"/usr/src/paperless/export",
"--zip",
"-zn",
"paperless_export",
],
capture_output=True,
text=True,
)
if result.stderr:
logger.error(f"Error creating paperless backup: {result.stderr}")
logger.info("Paperless backup created successfully.")
return "/home/bee/Documents/src/paperless/export/paperless_export.zip"
except Exception as e:
logger.error(f"Exception in create_paperless_backup: {e}")
return None
def restic_backup_backblaze():
path = create_paperless_backup()
try:
result = subprocess.run(
[
"AWS_SECRET_ACCESS_KEY=XXXX",
"AWS_ACCESS_KEY_ID=XXXX",
"restic",
"-r",
"s3:S3 BUCKET",
"backup",
"--compression",
"auto",
"-p",
"/home/bee/Documents/src/baccy/src/baccy/backblaze.txt",
path,
],
capture_output=True,
text=True,
)
if result.stdout:
logger.info(result.stdout) # Log the standard output
if result.stderr:
logger.error(result.stderr) # Log any errors
except Exception as e:
logger.error(f"Exception in restic_backup_ssd: {e}")
def restic_backup_ssd():
path = create_paperless_backup()
try:
result = subprocess.run(
[
"restic",
"-r",
"/mnt/portable_ssd",
"backup",
"--compression",
"auto",
"-p",
"/home/bee/Documents/src/baccy/src/baccy/password.txt",
path,
],
capture_output=True,
text=True,
)
if result.stdout:
logger.info(result.stdout) # Log the standard output
if result.stderr:
logger.error(result.stderr) # Log any errors
except Exception as e:
logger.error(f"Exception in restic_backup_ssd: {e}")
if __name__ == "__main__":
main() # Execute the Click command to parse arguments and run the backupNotification & Monitoring
Let's add some basic monitoring & notifications to our code.
Check out healthcheck.io :

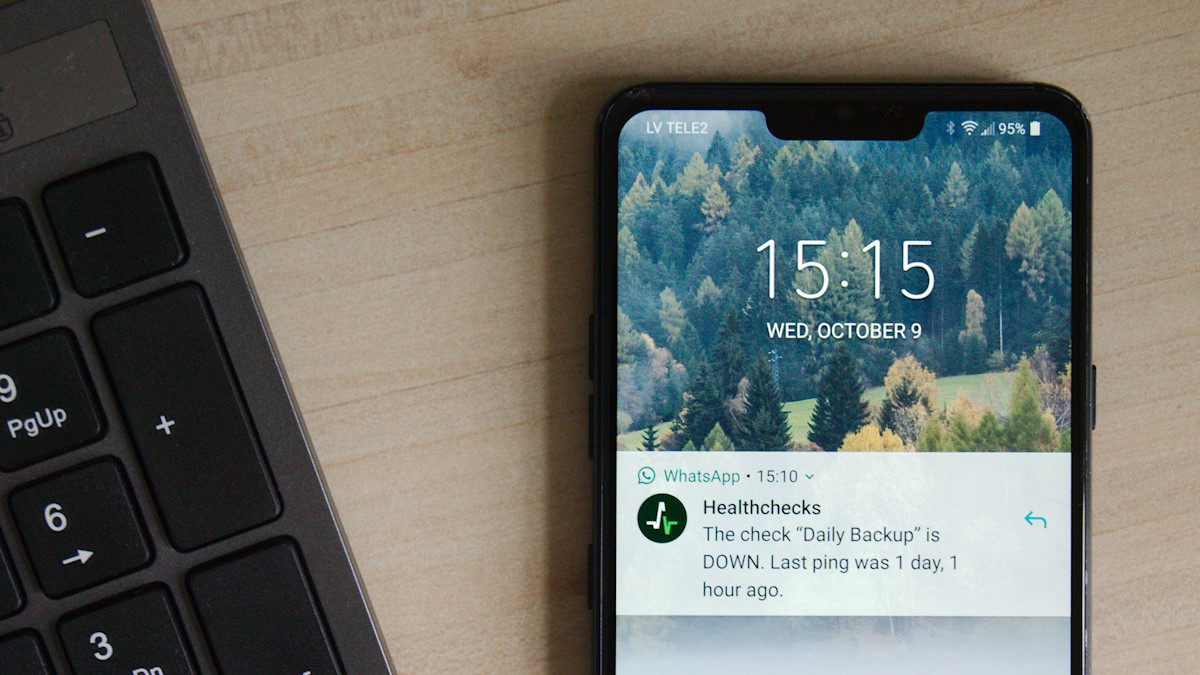
They give us a URL to ping, and if we do not ping that URL in a while they alert us.
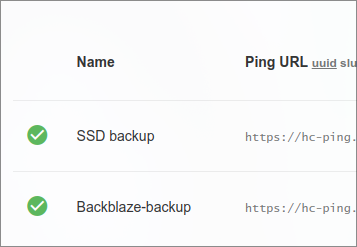
I set up 2 alerts.
- SSD backup
- Backblaze backup
My grace periods are:
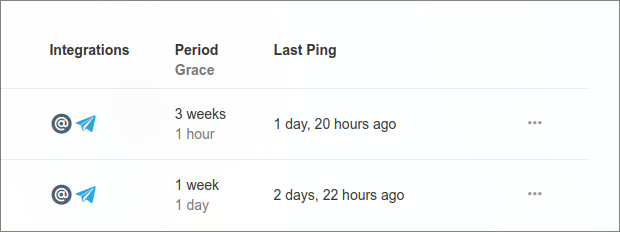
For Backblaze it's meant to back up once a week.
Not sure how often I'll plug my SSD in, so I have it set to alert every 3 weeks.
I've also set up OS level notifications using Hyperctl (I use Hyprland):
jhoblittNo guide here, but google "OS notification" to add it to your script!
Okay. so if we error out long enough we'll get alerted. That's nice.
But I'd like it to be really loud.
Telegram Bot
Let's make a quick Telegram bot that will yell at us.
I followed this tutorial to make a little bot:
Took like 1 minute.
BUT! Bots tend to reply to messages you send them.
I want our bot to message me first, not the other way around.
I followed this stackoverflow:

Now I have a bot that talks to me about backups:
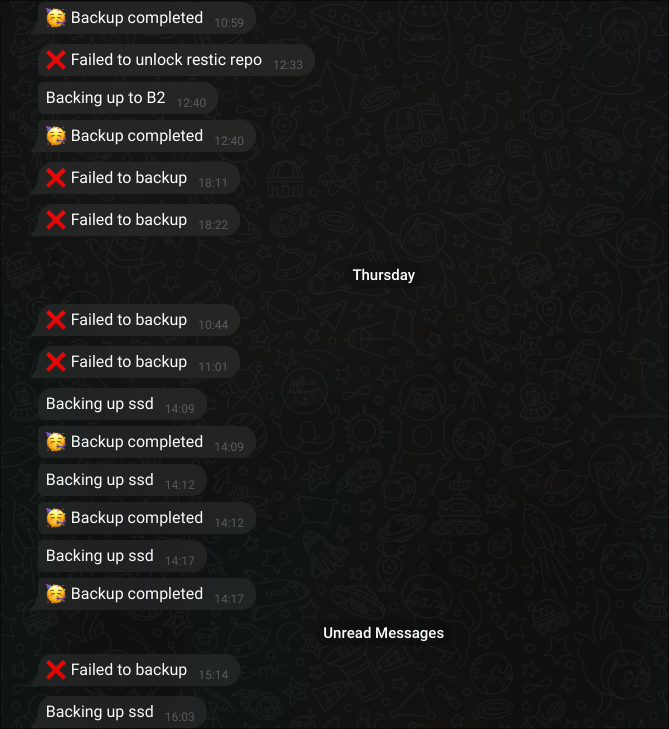
I figured the most important things I need to know are:
- When is it backing up?
- Is it done yet?
- Did it fail? 🤔
I don't really need it to tell me the reason it failed because I can just run journalctl on my computer to get that information 🥳
SSD Encryption
Okay so I'm a bit unhappy with my SSD encryption.
It's file level using Restic, which is good.
But....
My threat model is someone takes my SSD. If they can read the files on the SSD (they can, they just can't decrypt it) they may get curious.
They may copy the files over to their desktop.
Restic may experience a bug in the future and I may get compromised due to it :(
Soooo let's use full disk encryption!
When an attacker plugs a drive into Windows / Mac with full disk encryption, the OS will say:
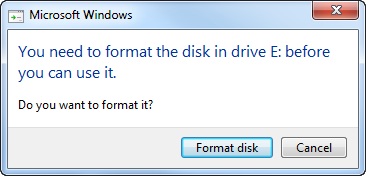
"You need to format the disk before you can use it"
If you are an attacker who steals things, you will likely click "format" as you have no reason to think anything else. And poof! My data is safely gone 🥳
What I want is:
- 2 paritions
- Partition 1, 100gb, unencrypted
- Partition 2, 1.9tb, encrypted

In Windows file formatter (I prefer it over any Linux tools) I format my SSD into 2 parts:
- Partition 1 = 100gb
- Partition 2 = 1.9tb
Then I used Veracrypt to encrypt the 1.9tb partition:

The reason I use Veracrypt is because unlike Bitlocker & LUKs, it's cross-platform and has a portable version of the app.
I don't need to write much here, just follow Veracrypt for now! 🥳
Once done, you'll notice if you unplug the USB and back in Windows will say...
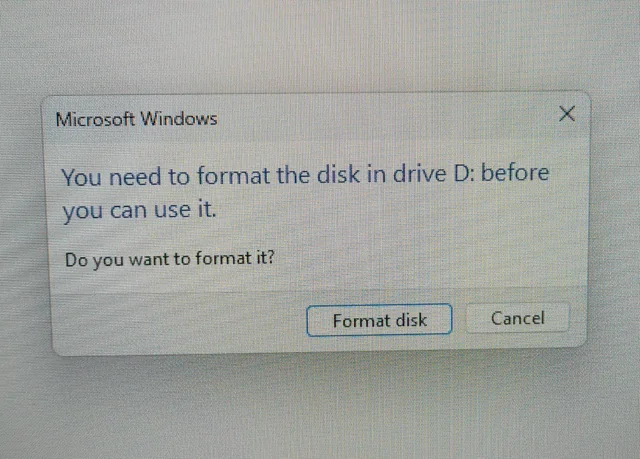
Amazing!!!
Now let's do something cool. Let's automount it and auto-decrypt it on Linux so we can back up automatically, and do all of this automatically (automatically will be the buzzword of 2025)
I don't mind storing passwords in plaintext on Linux because my OS is very encrypted too, and I plan on using Bitwarden CLI to automatically grab them eventually™️
Let's run this command:
❯ lsblk -o NAME,UUID,MOUNTPOINT /dev/sda
NAME UUID MOUNTPOINT
sda
├─sda1 A4E2-600C
└─sda2
I am thinking our udev rule needs editing, so let me double check.
❯ sudo cat /etc/udev/rules.d/99-portable-ssd.rules
ACTION=="add", SUBSYSTEM=="block", ENV{ID_MODEL}=="Extreme*", ENV{ID_SERIAL_SHORT}=="32343133464E343031373736", ENV{ID_PART_TABLE_UUID}=="2d5cd6d0-fe65-4259-86dc-3bedb545dbbb", TAG+="systemd", ENV{SYSTEMD_WANTS}="automatic-backup.service"We do not use kernel here (which is /dev/sda) so it should be good....
We can tell our Python script to automatically unlock the SSD instead of making a new rule. Let's just test if it works:

Wow! It just works. That's a first in my career 😆
def unlock_ssd():
os.system(
f'veracrypt --text --non-interactive --mount /dev/sda2 /mnt/secure --pim=0 --password="{secrets.veracrypt}" --keyfiles=""'
)
I had an issue where I couldn't unlock it unless I was sudo.
I ran sudo visudo and added this:
bee ALL=(ALL) NOPASSWD: /usr/bin/veracrypt, /bin/mountThis says "When I run veracrypt / mount as sudo, do not ask for a password". Veracrypt also uses mount, so I added that here.
Now when I plug the SSD back in....

Amazing! We have full disk encryption, which decrypts automatically, backs up, and unmounts for us! 🥳
Final Script
For readers who want to copy my code, here it is!
#!/usr/bin/env python3
import subprocess
import logging
import sys
import click
import requests
import requests
import os
import secrets
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger = logging.getLogger()
def check_website_accessibility(url):
try:
response = requests.get(url, timeout=5)
if response.status_code == 200:
return
else:
logger.error(f"{url} returned status code {response.status_code}.")
send_telegram(f"❌ Backblaze responded with {response.status_code}")
exit(1)
except requests.exceptions.RequestException as e:
logger.error(f"Could not access {url}. Reason: {e}")
send_telegram("❌ Failed to connect to internet")
exit(1)
def hyperctl(message):
os.system(f'hyprctl notify 5 10000 "fontsize:35 {message}"')
def send_telegram(message):
token = secrets.baccybot
chatid = secrets.chatid
url = f"https://api.telegram.org/bot{token}/sendMessage?chat_id={chatid}&text={message}"
try:
requests.get(url).json()
except Exception as e:
logger.error("Failed to send telegram message")
def make_packages():
os.system("sh /home/bee/Documents/src/baccy/src/baccy/backup_pacman.sh")
def unlock_ssd():
try:
result = subprocess.run(
[
"sudo",
"veracrypt",
"--text",
"--non-interactive",
"--mount",
"/dev/sda2",
secrets.ssd_mnt,
"--pim=0",
"--password",
secrets.veracrypt,
"--keyfiles",
"",
],
check=True,
capture_output=True,
text=True,
)
if result.stderr:
logger.error("Can't unlock SSD with veracrypt: %s", result.stderr)
send_telegram("❌ Failed to unlock SSD with veracrypt: " + result.stderr)
exit(1)
except subprocess.CalledProcessError as e:
logger.error("Couldn't unlock SSD with veracrypt: %s", e.stderr or e.output)
send_telegram(
"❌ Failed to unlock SSD with veracrypt: " + (e.stderr or e.output)
)
exit(1)
def unmount_ssd():
try:
result = subprocess.run(
[
"sudo",
"veracrypt",
"--text",
"--non-interactive",
"--dismount",
secrets.ssd_mnt,
],
check=True,
capture_output=True,
text=True,
)
logger.info("SSD unmounted successfully")
except subprocess.CalledProcessError as e:
logger.error("Can't unmount SSD: %s", e.stderr or e.output)
send_telegram("❌ Failed to unmount SSD: " + (e.stderr or e.output))
exit(1)
def make_immich_db_backup():
try:
# Open the output file to write the gzipped dump directly
with open("/tmp/immich_db_dump.sql.gz", "wb") as outfile:
process = subprocess.Popen(
[
"docker",
"exec",
"-t",
"immich_postgres",
"pg_dumpall",
"--clean",
"--if-exists",
"--username=postgres",
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
logger.info("Running pg_dumpall command and compressing output with gzip")
# Pipe stdout through gzip and write to file
gzip_process = subprocess.Popen(
["gzip"],
stdin=process.stdout,
stdout=outfile,
stderr=subprocess.PIPE,
)
# Read and log stderr from the primary process
for line in process.stderr:
logger.error(line.decode().strip())
# Wait for both processes to complete
process.wait()
gzip_process.wait()
if process.returncode != 0:
logger.error(
f"pg_dumpall process exited with code {process.returncode}"
)
send_telegram("❌ Failed to backup")
exit(1)
if gzip_process.returncode != 0:
logger.error(f"gzip process exited with code {gzip_process.returncode}")
send_telegram("❌ Failed to compress backup")
exit(1)
except Exception as e:
logger.error(f"Exception in pg_dumpall_backup: {e}")
send_telegram("❌ Failed to backup")
exit(1)
@click.command()
@click.option("--ssd", help="Runs the ssd backup commands", is_flag=True)
@click.option("--backblaze", help="backsup to backblaze", is_flag=True)
def main(ssd, backblaze):
make_packages()
make_immich_db_backup()
if ssd:
hyperctl("Backing up to SSD")
send_telegram("Backing up ssd")
logger.info("SSD backup has been chosen")
unlock_ssd()
send_telegram("SSD unlocked and unmounted with Veracrypt")
ssd_backup()
unmount_ssd()
if backblaze:
send_telegram("Backing up to B2")
check_website_accessibility("https://backblaze.com")
hyperctl("Backing up to B2")
logger.info("Backblaze backup has been chosen")
backblaze_backup()
hyperctl("Backup complete")
send_telegram("🥳 Backup completed")
logger.info("Backup process completed.")
def create_paperless_backup():
try:
result = subprocess.run(
[
"docker",
"exec",
"paperless",
"document_exporter",
"/usr/src/paperless/export",
"--zip",
"--no-progress-bar",
"-zn",
"paperless_export",
],
capture_output=True,
text=True,
)
if result.stderr:
logger.error(f"Error creating paperless backup: {result.stderr}")
send_telegram("❌ Failed to create Paperless backup")
exit(1)
logger.info("Paperless backup created successfully.")
return "/home/bee/Documents/src/paperless/export/paperless_export.zip"
except Exception as e:
logger.error(f"Exception in create_paperless_backup: {e}")
send_telegram("❌ Failed to create Paperless backup 2")
exit(1)
def backblaze_backup():
location = secrets.backblaze
password = "/home/bee/Documents/src/baccy/src/baccy/backblaze.txt"
logging.info("backing up")
unlock(location, password)
backup(location, password)
logger.info("pruning backblaze")
prune_and_check(location, password)
requests.get("https://hc-ping.com/be1e1344-4902-46bc-ab42-78799cc11316")
def ssd_backup():
location = secrets.ssd_mnt
password = "/home/bee/Documents/src/baccy/src/baccy/password.txt"
unlock(location, password)
backup(location, password)
logger.info("pruning ssd")
prune_and_check(location, password)
requests.get("https://hc-ping.com/a8131ae4-00a5-46ae-bd0c-c0b211046f29")
def unlock(location, password):
try:
process = subprocess.Popen(
[
"restic",
"-r",
location,
"-p",
password,
"unlock",
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1, # Line-buffered output
)
logger.info("running command and printing output as it becomes available")
# Print stdout as it becomes available
for line in process.stdout:
logger.info(line.strip()) # Log each line of standard output
# Print stderr as it becomes available
for line in process.stderr:
logger.error(line.strip()) # Log each line of standard error
process.wait() # Wait for the process to complete
if process.returncode != 0:
logger.error(f"Backup process exited with code {process.returncode}")
except Exception as e:
logger.error(f"Exception in unlock: {e}")
def backup(location, password):
try:
process = subprocess.Popen(
[
"restic",
"-r",
location,
"backup",
"--compression",
"auto",
"--skip-if-unchanged",
"-p",
password,
"--files-from",
"/home/bee/Documents/src/baccy/src/baccy/backup_locations.txt",
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1, # Line-buffered output
)
logger.info("running command and printing output as it becomes availabl")
# Print stdout as it becomes available
for line in process.stdout:
logger.info(line.strip()) # Log each line of standard output
# Print stderr as it becomes available
for line in process.stderr:
logger.error(line.strip()) # Log each line of standard error
process.wait() # Wait for the process to complete
if process.returncode != 0:
logger.error(f"Backup process exited with code {process.returncode}")
send_telegram("❌ Failed to backup")
exit(1)
except Exception as e:
logger.error(f"Exception in restic_backup_ssd: {e}")
send_telegram("❌ Failed to backup")
exit(1)
def prune_and_check(location, password):
try:
result = subprocess.run(
[
"restic",
"forget",
"-r",
location,
"--keep-monthly",
"12",
"--keep-daily",
"30",
"--keep-yearly",
"2",
"-p",
password,
],
capture_output=True,
text=True,
)
if result.stdout:
logger.info(result.stdout) # Log the standard output
if result.stderr:
logger.error(result.stderr) # Log any errors
send_telegram("❌ Failed to prune")
exit(1)
except Exception as e:
logger.error(f"Exception in prune and check: {e}")
send_telegram("❌ Fail in prune")
exit(1)
try:
result = subprocess.run(
["restic", "check", "-r", location, "-p", password],
capture_output=True,
text=True,
)
if result.stdout:
logger.info(result.stdout) # Log the standard output
if result.stderr:
logger.error(result.stderr) # Log any errors
send_telegram("❌ Failed to check")
exit(1)
except Exception as e:
logger.error(f"Exception in restic_backup_ssd: {e}")
send_telegram("❌ Failed to check")
exit(1)
if __name__ == "__main__":
main()I have 2 more files:
backup_locations.txt is a file like:
/usr/src
/bin
/tmpOf places to backup.
cat backup_pacman.sh
mkdir -p /tmp/pkglists
pacman -Qqem > /tmp/pkglists/pkglist-repo.txt
pacman -Qqem > /tmp/pkglists/pkglist-aur.txt❯ cat secrets.py
import os
os.environ["AWS_SECRET_ACCESS_KEY"] =
os.environ["AWS_ACCESS_KEY_ID"] =
password_backblaze =
password_ssd =
baccybot =
chatid =
backblaze =
veracrypt =
ssd_mnt = Conclusion
Okay now we have a stupidly complex backup system.
The only thing left to do is test that our backups work 😆
If you do not test your backups, you may as well have not backed up at all!