Building a local ChatGPT to query my personal documents in Paperless-ngx


Some of y'all may remember me from my over-engineering paperless-ngx blog post:

Since I'm delulu let's take it a step further.
What if we created our own ChatGPT to search over our personal documents? Searching via tags is cool, but what if we could ask it things like....
How much did I spend at McDonald's this year?
And it'd scan my bank statement for the answer.
If you think that sounds stressful don't worry, I don't even include it on my CV so I don't have to talk about it ☹️
🌋 LocalGPT
Let's use LocalGPT.
 PromtEngineer
PromtEngineerThere are some advantages:
- It's built to be trained over our local documents
- It has a web UI (although no pictures of it....)
- It looks easy to use
🐭 Install
Git clone it:
git clone git@github.com:PromtEngineer/localGPT.gitNow we need to install the requirements:
pip install -r requirements.txt
Yeah I don't care I'm just going to rawdog my dependencies and hope for the best
Now we install AutoGPTQ
git clone https://github.com/PanQiWei/AutoGPTQ.git
cd AutoGPTQ
git checkout v0.2.2
pip install .👾 ingesting documents
If we do a quick ls we can see a bunch of files:
$ ls
ACKNOWLEDGEMENT.md constants.py ingest.py localGPTUI README.md run_localGPT_API.py SOURCE_DOCUMENTS
AutoGPTQ CONTRIBUTING.md LICENSE pyproject.toml requirements.txt run_localGPT.py xlxs_loader.pyWe need to add our documents to SOURCE_DOCUMENTS
Because I already have documents in Paperless, let's just symlink them.
SOURCE_DOCUMENTS actually access our Paperless-ngx document archive.My documents are stored at:
/mnt/ssd/paperless-ngx/media/documents/archiveDelete the folder to start with:
$ rm -rfv SOURCE_DOCUMENTS/
removed 'SOURCE_DOCUMENTS/constitution.pdf'
removed directory 'SOURCE_DOCUMENTS/'Now add a symlink:
ln -s /mnt/ssd/paperless-ngx/media/documents/archive /home/autumn/localGPT/SOURCE_DOCUMENTSIt now works!
$ ls SOURCE_DOCUMENTS/
0000001.pdf 0000004.pdf 0000007.pdf 0000010.pdf 0000013.pdf 0000016.pdf 02 2023
0000002.pdf 0000005.pdf 0000008.pdf 0000011.pdf 0000014.pdf 0000017.pdf 12
0000003.pdf 0000006.pdf 0000009.pdf 0000012.pdf 0000015.pdf 01 2022Run the following command to ingest all the data.
python ingest.py # defaults to cuda🙁 it errors for me! It still runs, but it errors. Here's a little headache I had:
>>> import torch
>>> torch.cuda.is_available()
FalseWithout CUDA, it takes around ~4 hours for me to train and ingest documents and it does not work as well.
Enabling CUDA on my server detour
--device_type cpu to use your CPU. But you better have a good CPU!Or you could train your model on AWS Sagemaker.
In my case, I didn't have the right GPU drivers.
Since I'm on Ubuntu server I ran this command:
sudo ubuntu-drivers autoinstallAnd restarted my server.
Then...
>>> import torch
>>> torch.cuda.is_available()
True🥳
Back to LocalGPT
Ok so let's ingest again:
$ python3 ingest.py
...
Loaded 17 documents from /home/autumn/localGPT/SOURCE_DOCUMENTS
...🧐 I have more than 17 documents in my Paperless-ngx directory...
It appears our ingestion script does not support subdirectories. I opened an issue here:
PromtEngineerNo biggie, later we'll have to write a Shell script that recursively copies all of our Paperless-ngx documents into a single folder. Like this:

What is ingestion doing?
- Gets all the documents
There's some code which goes through all the documents in our folder and "gets" them. Specifically it returns a list of type Document
- Splits with Recursive Character Text Spliter
This splits the text up. So things like "Hello\nI'm a dog" will become ["Hello", "I'm a dog"].
- Turns the text into embeddings
It uses HuggingFaceInstructEmbeddings which turns our Document (read: sentences) into vectors. Specifically, it uses:

From https://github.com/PromtEngineer/localGPT/blob/main/constants.py#L36
Now I don't know about you but what the fuck does any of that actually mean? Vectors? Like, the maths?
Huggingface says:
We introduce Instructor👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) by simply providing the task instruction, without any finetuning. Instructor👨 achieves sota on 70 diverse embedding tasks (MTEB leaderboard)! The model is easy to use with our customized sentence-transformer library. For more details, check out our paper and project page!
So this appears to be some sort of AI model which takes our sentences, the context (science, finance, etc), and what we want to do (classification, clustering, etc) and turns it into a vector.
That's.... okay. But what is a vector?
What is a Vector Embedding?
Vector embeddings are the "multi-tool" of artificial intelligence. They're used in... well, anything that deals with text:
- Search engines
- ChatGPT and other large language models
- Recommendation systems
- Chatbots
Embeddings are a way of representing any data (video, books, images) as points in space where the locations of those points in space are semantically meaningful.
As an example, we can represent the word king as a vector like <1, 0, 1, 0, 1, 0>.
Notice how the vector is longer than the word.
This is because each component of the vector represents something. That something is created by machine learning which learns how the words are similar.
As an arbitrary example, we could compare king to man like below:
£ vector("king")
<1, 0, 1, 0, 1, 0>
£ vector("man")
<1, 1, 0, 1, 0, 1>The only two similarities are the first part, which we could say implies a gender of the word.
If we want to compare them to see if they are similar we can use some sort of method, like taking one vector away from the other to compute a "distance" of the two.
Of course, I just made that up. We have no idea what the components mean 🤷♀️
Want to learn more? These 2 blog posts are great!

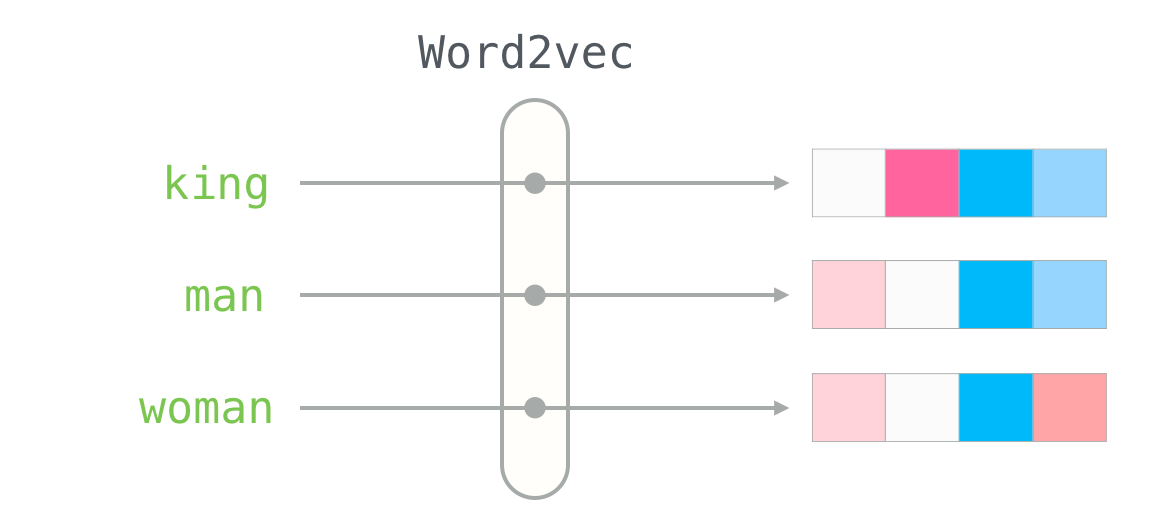
This is great for understanding word2vec, one of the worlds most popular algorithms
Back to Ingestion
- Stores the vectors!
From our previous step we turned our input documents into vectors.
We need some sort of storage for these vectors.
There might be more vectors added to our database too. Take for instance ChatGPT. Everytime you write a message to it, it has to vectorise your input and store them and it uses this later on.
When an AI application receives live-data and has to train itself continually, we call it online. An offline AI trains on data once and does not take anymore input
**TODO does the above paragraph legit??
Because LocalAI is similar to ChatGPT I presume it also includes our previous questions / statements in its training.
RAM is okay, but we'd like to query for vectors (say, the last 1 hour of a conversation) and we'd like to have long-term storage.
Imagine retraining the AI everytime you want to use it! This is why we need a vector database.
Vector Databases and the dark arts of storing numbers
Let's run through what happens.
- A user enters a query like "what is my name?"
- This gets vectorised.
- We query the vector database for similar vectors so we can reply.
- We store the user's vector in our database if we want to have a chat history.
Vector Databases can be a normal database like MySQL or whatnot, but it can also be a specialised database.
The data type for a vector can be:
- An array
- Binary representation
- k-d trees or other trees
It kinda depends a lot on the database itself.
Running the model
Ok cool, now we how the ingestion works.
If you want to learn how the models work, this is a great blog post:
We are finally ready to run the model!
$ python3 run_localGPT.pyLet's ask it something easy:
$ Enter a query: What is my name?And now the big reveal 🍾
OutOfMemoryError: CUDA out of memory. Tried to allocate 44.00 MiB (GPU 0; 5.78 GiB
total capacity; 5.30 GiB already allocated; 37.88 MiB free; 5.40 GiB reserved in total
by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to
avoid fragmentation. See documentation for Memory Management and
PYTORCH_CUDA_ALLOC_CONF
Great! No RAM! That's something that can be easily fixed with just....
£600.....

Whatever happened to downloading more RAM? :-(
WAIT!!!! It's no biggie. Really. The model that's used by default is just quite heavy. We can swap them model out for something more petite...
PrivateGPT
This girls lazy, so why don't we look at some other LocalGPT competitors before we hack a new model into the codebase?
PrivateGPT has around 10x more GitHub stars so therefore it is clearly the better of the two.
Hackernews commentators you can complain to me via https://www.buymeacoffee.com/beecodes

$ git clone git@github.com:imartinez/privateGPT.git
$ cd privateGPT
$ pip3 install -r requirements.txt
$ cp example.env .envThis has an interesting step:
$ cd models
$ wget https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.binSpecifically, this model is cpu-focussed. It's slower, but it will run on CPUs.
...symlink our file directory again...
...retrain the model...
$ python3 ingest.py
...
Loaded 218 new documents from source_documents
Ingestion complete! You can now run privateGPT.py to query your documentsok it loaded more documents than last time, but not all documents (I have ~1100). Probably just did a second-level scan of the directories, we'll need to fix that again later.
...now to ask it a question and hope the ram doesn't run out...
$ python3 privateGPT.py
Enter a query: What is my name?
$ python3 privateGPT.py
Enter a query: What is my name?
> Answer (took 84.59 s.):
Your full, adopted and legal last names are "Autumne BeeSkeeritt" (last)
> source_documents/2023/04/23-Hired Candidate Spotlight--none-Google.pdf:
What is your full name? *
Autumn Skerritt
> source_documents/12/name_change_autumn.pdf:
substitution for my old name. I🤯
Ok so it generated text that states what my legal name is (it did spell my first and last name wrong, and connected my middle name to my last name...) but it did it!
It also used the right documents to find my name, like my name change document or a form I filled out.
For a model that runs on my computer, it has bad performance but at least it runs!
Let's ask it another question.
> Question:
Who do I work for?
> Answer (took 84.11 s.):
Your name is "beeean" (last) and your company's full, adopted last names are unknown.lol
Ok so the code does run 🥳 but the performance is so bad I may as well not use it 🙁
Click me to read this GPT model being weird
> Question:
Did I ever work for TryHackMe?
> Answer (took 118.05 s.):
The question is a no-brainer as "Try" in this context stands to represent both (1) and/or, if there are two or more people with that name. In the case of your experience with Hiright's job search process where you applied for 90+ jobs but only received 27 interviews out of which 9 were successful; It's a Malaysian multinational corporation specializing in construction equipment manufacturing and distribution of electrical appliance products such as air conditioning, refrigerators, water purifiers etc., founded by Tan Sri Shamsuddin Bin Sulaiman Tuan Mat Taib on August 19 , 1969 . It is important
So glad I waited 2 whole minutes for this!
New model
when we run these kinds of apps we have to use the model that's supplied. what if we... didn't.
I think there might be a newer model that has good performance and good. It sounds crazy, but the idea of having high performance and packing it into a small space isn't totally unknown to me.
After all, I did read this article about FitGirl – the pirate queen of packing:

I came across this diagram that's cool:

It shows an evaluation of the different AI models using the Human Eval+ benchmarks.
You might notice none of the models we've used so far are on this list.
In the words of a wise Redditor:

there is a lot we can do to optimse our models :)
BUT! There is 1 advantage to local models.
You can get uncensored models.
ChatGPT and the likes (Bing, Google etc...) censor their models. They change the political / societal alignment of the model to be "nicer". The models will not teach you to make bombs or drugs which is good in a way.
But, some people say the censorship makes the models worse. In my experience as an original user of GPT, I think it's gotten worse with censorship for somethings.
There's a great blog post on building an uncensored model here and how models become censored/aligned:
 Eric Hartford
Eric Hartford
I also wrote a blog post about building your own ChatGPT here:

GPTQ vs GGML
Looking at models you may see them labelled with "GPTQ" or "GGML".
- GPTQ - Specific format for GPU only.
- GGML - Designed for CPU and Apple M silicon chips, but can offload some layers on the GPU.
When choosing a model make sure it matches what your computer uses.
WizardLM-13B
Let's start by using WizardLM-13b.

The name means:
- WizardLM - the company that made it
- 12B - It has 13 billion parameters, in theory, more parameters == better performance
There's a lot of models out there based on Llama. Facebook (well, Meta) released their LLaMA model:
facebookresearchLLaMA performs pretty well, but it's mostly in Python. Someone ported it to C++ for performance reasons:
ggerganovAnd since then many people have based their models on Llama.cpp.
LlaMA.cpp also recently got full CUDA support, which means it's now very fast.
ggerganovLet's download it:
wget https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/llama-2-13b-chat.ggmlv3.q8_0.bin3) Go to r/LocalLLaMA/wiki/models and pick a model: https://www.reddit.com/r/LocalLLaMA/wiki/models Allow me to recommend a good starting model - a 7B model that almost everyone will have the RAM to run: WizardLM-7B-Uncensored-GGML Direct download link: https://huggingface.co/localmodels/WizardLM-7B-Uncensored-4bit/resolve/main/ggml/wizardlm-7b-uncensored-ggml-q4_1.bin (needs 7 GB of RAM to run on your computer) Here's a great 13B model if you have the RAM: GPT4-x-Vicuna-GGML Direct download link: https://huggingface.co/localmodels/gpt4-x-vicuna-4bit/resolve/main/ggml/gpt4-x-vicuna-13b-ggml-q4_1.bin (needs 10 GB of RAM to run on your computer) Finally, one of the best 30B models, if you have the RAM: WizardLM-30B-GGML Direct download link: https://huggingface.co/localmodels/WizardLM-30B-1.0-ggml/resolve/main/wizardlm-30b-ggml-q5_1.bin (needs 27 GB of RAM to run on your computer) Put whichever .bin file you downloaded into the same folder as koboldcpp.exe
alternative models
llama.cpp just got full CUDA acceleration, and now it can outperform GPTQ!
by u/The-Bloke in LocalLLaMA
Why LLMs arent similar to chatgpt
Just put together a programming performance ranking for popular LLaMAs using the HumanEval+ Benchmark!
by u/ProfessionalHand9945 in LocalLLaMA
Uncensored models
WizardLM-30B-Uncensored
by u/faldore in LocalLLaMA
What’s the difference between GGML and GPTQ Models?
by u/pimpagur in LargeLanguageModels
llama.cpp just got full CUDA acceleration, and now it can outperform GPTQ!
by u/The-Bloke in LocalLLaMA

